
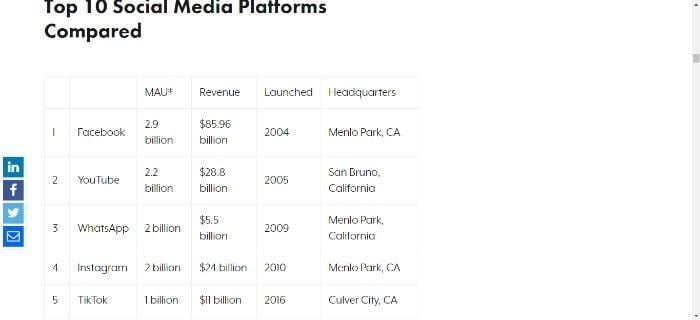
TikTok has steadily become one of the most popular social media apps.
According to data from Sensor Tower, TikTok now surpasses three billion downloads, and it’s the only non-Facebook app to achieve this.
Consumer spending within TikTok is looking pretty rosy, too, with TikTok surpassing $2.5 billion worldwide.
There appears to be no stopping the social media juggernaut that is TikTok, and as its popularity grows, so does the question of getting on the FYP.
If you’re new to the social media giant, the TikTok FYP consists of curated content that users see when they log in.
This article will answer how to get your TikTok on the FYP and teach you everything you need to know about the site’s mysterious algorithm and how to use it to your advantage.
However, first, let’s begin with the basics.
What Is TikTok?
TikTok is an iOS and Android social media app for creating and sharing short 15 to 60-second videos on any topic.
In 2016, the app launched as Douyin in China, and in the following year, ByteDance released it for markets outside of China as Musical.ly before rebranding to TikTok.
Now, the app boasts one billion active users, making it the fifth-largest social media site in the world.
Why is TikTok so Popular?
While it started as a fun lip-syncing app with a cult Gen Z following, it’s evolved into a way for users to share short comedy skits, business tips, and more.
As the newest social media app on the block, it could be much easier to grow a following on TikTok than on over-saturated sites like Instagram and Facebook with restricting algorithms.
TikTok also lends itself well to how we consume our content these days. With 6.6 billion smartphone users out there, TikTok’s bite-sized format is perfect for those that want to watch their content on the go.
Naturally, with the popularity of TikTok, and a keen audience, businesses are flocking to the platform. Some of the high-profile companies there include Nando’s, Levis, and BMW.
In addition, TikTok offers powerful tools for businesses to measure their performance and track engagement, allowing companies to see which videos are performing well and better understand their audience preferences. With this data, companies can create more compelling content strategies for future campaigns and grow their followings.
What Is the FYP On TikTok Designed For?
The For You page, aka “FYP,” is the first page you land on when you open the TikTok app. It’s a curated feed of videos from creators you might not follow, but TikTok’s algorithm thinks you will like them based on your interests and past interactions.
Several factors contribute to the content you see on the TikTok FYP. Each feed is unique and stems from the types of content you watch and the interest you state as a new user.
Other factors include:
- Information from videos, like captions and hashtags.
- Device settings, such as language preference, country settings, and your device type.
- The types of content you share, like, follow and create, along with the comments you add.
For example: If you like and leave comments on several videos about Instagram tips, you can expect to see a fresh serving of social media marketing TikToks on your For You page every day.
Think of it as the Instagram Explore Page. The app wants to hook you in with more content you like to keep you scrolling longer.
Why You Should Optimize Your Content for the TikTok FYP
The TikTok For You page showcases the best content from around the platform. It’s also where users go to discover new content. It’s simple: if you want users to find your business or content, you need to be in the mix.
To further enhance your chances of getting your content on TikTok’s FYP, you can optimize your content to get more views and followers.
That’s why many consider the TikTok FYP as the ‘holy grail’ of success on the app. After all, it means you’ve created a piece of content that resonates with your audience, and it’s attracting attention.
The algorithm picks this up and recognizes your content’s quality above all the other videos on the app.
What this means for business owners and influencers:
- Followers and Monetization: By landing on the TikTok FYP, you could gain followers faster and get closer to the 10k goal. Once you hit that milestone, you can start making money from your videos with the TikTok Creator Fund.
- Sponsorships, Thought Leadership, and Sales: Once the algorithm starts pushing out your video to a broader audience, you might start getting more recognition as a master of your niche. This can lead to paid sponsorships or more sales in your business.
- Platform Growth: Ever heard the saying, “it takes a platform to grow a platform?” Once you’ve struck TikTok gold, you can use the attention to redirect traffic back to your other platforms like Instagram or YouTube and start growing your community across the board.
- Free Exposure: If you usually get 100 views per TikTok, an FYP feature could push that to tens of thousands. It’s incredible exposure you can leverage without spending a dime on ads.
In addition, you can reach your target market, share your messaging and use it for relationship building.
3 Ranking Factors That Determine How To Get Your TikTok on The FYP
For years, the TikTok FYP algorithm was cloaked in mystery. Rumors and speculation flew around the internet, sparking the rise in hashtags like #fyp and #ForYou, until TikTok HQ came out with a statement settling the debate once and for all.
In a community post, TikTok states:
On TikTok, the For You feed reflects preferences unique to each user. The system recommends content by ranking videos based on a combination of factors – starting from interests you express as a new user and adjusting for things you indicate you’re not interested in, too – to form your personalized For You feed.
Here are the nitty-gritty details of the TikTok algorithm and how the For You page works.
1. User Interactions
The more comments, likes, shares, and duets your video gets, the more likely the algorithm will pick it up.
Another ranking factor you need to keep in mind is your video completion rate. As more users watch your TikTok to the end, it’s more likely to get pushed out for further distribution.
2. Video Information
Hashtags, sounds, and captions are a treasure trove of information to help you get onto the For You page. For instance, if you use a trending hashtag or sound bite, it’s more likely to get noticed by the algorithm.
Remember, TikTok’s goal is to keep people on the app, and serving trending content is one way to do that.
3. Device and Account Settings
Your location, language preference, device, and country setting play a role in curating your TikTok FYP. After all, a comedy skit about South African politics would probably only appeal to South African users.
However, these signals don’t have as much weight as the others, giving you the chance to reach a global audience.
Before wrapping up this section, just a quick note:
You also want to avoid duplicate content. It’s tempting to repeatedly share the same content, like some do on Twitter. for businesses leading to wasted time and resources but also decreased engagement as TikTok won’t recommend duplicated content.
Finally, if you’re new to TikTok or have yet to create any viral content, don’t worry because TikTok doesn’t consider any of this.
Eight Tips to Get on the TikTok For You Page (FYP)
There is no bulletproof recipe for success on TikTok or any other social media network. Algorithms are constantly changing, and if your content doesn’t resonate with your audience, it won’t rank.
However, you can do several things to improve your chances of hitting TikTok’s FYP:
Let’s start with the basics:
- It’s important to optimize your videos for search engine optimization (SEO). This means including keywords in your titles and descriptions so that people looking for content like yours are more likely to find it.
- To get started, research to find out which keywords are most relevant to your topic. Then, use those keywords throughout your video title and description. You can also include them in the tags section of the app.
- Use creative visuals. Since the main purpose of the app is to watch short videos, it’s important to include effects that capture people’s attention.
- Add subtitles for greater accessibility.
1. Use Proper Hashtag Etiquette
Some users believe using #fyp or #ForYou will get their content pushed out to the masses, but it’s only a rumor. TikTok has never confirmed this, and these hashtags don’t guarantee you any viral success.
You don’t want to use those hashtags as a crutch and miss out on using keywords relevant to your content and niche.
After all, the main goal of social media is to attract the right followers and then monetize your audience.
Here are some basic TikTok hashtag rules to follow:
- Don’t hashtag stuff. Choose a small number of relevant hashtags.
- Mix popular hashtags with less popular ones.
- Use trending hashtags in your niche.
- Participate in hashtag challenges.
- Use #fyp and #ForYou, but don’t only rely on them.
Remember, there is no tried-and-true formula, so as on Instagram, you’ll need to experiment to find a hashtag strategy that works best for your account.
2. Create Shorter Videos
Remember when I told you how vital the video completion rate is on TikTok? Creating shorter, engaging videos is the easiest way to achieve top marks for this ranking factor.
Although you can record 60-second clips, using all the time available won’t necessarily translate into viral success. The less time someone spends watching your TikTok, the more likely they’ll watch to the end and not swipe away.
You can improve your watch time by ensuring you have a hook right in the beginning to encourage viewers to stay until the end.
As your video completion rate increases, so do your chances of landing a coveted spot on the TikTok FYP.
Here are some tips for creating awesome videos:
- Keep it simple. The best TikTok videos are those that are simple and easy to follow.
- Use creative transitions. Try using some of the app’s built-in transitions, or develop your ideas.
- Be funny and entertaining if it suits your overall tone. The best TikTok videos are those that are entertaining and make people laugh. Be creative and think of original ways to grab people’s attention.
- Engage with your viewers – Be interactive with your viewers and reply to their comments. This helps create a community around your content.
3. Write Engaging Captions
TikTok is not the platform to spill your guts in a microblogging session.
You only get 150 characters, including any hashtags you add, which leaves you with fewer characters at your disposal than on Twitter.
With such limited real estate, you need to focus on writing short captions that compel viewers to engage with your content.
The ideal TikTok caption should:
- Be short
- Feature related hashtags
- Encourage engagement
How do you do this?
You could stir up some mystery by saying something like, “this took me five attempts to get right,” or “wait until the end.” This could encourage viewers to stick around and watch the entire video.
Another tactic is to ask a question. Comments are another engagement factor, and getting people to watch and reply can help send all the right signals to the FYP algorithm.
Lastly, you can tease viewers with the information you’re revealing in your video. For example, “How I find clients as a freelance writer” or “One easy hack to make $100 online.”
4. Create High-Quality Videos
Are you still posting grainy, low-quality videos on TikTok? That might be one of the reasons you haven’t earned a spot on the For You Page.
A high-quality video is more likely to keep eyeballs on your content, which means higher completion rates and more views.
TikTok isn’t going to push out low-definition, blurry, or grainy videos to the masses. At best, it could cause users to swipe away; at worst, people will close the app.
With most smartphones offering HD video, it’s easier than ever to produce high-resolution videos without a big budget or full production team.
Besides the quality of your content, the platform also rewards editing skills. Experiment with filters, stickers, and transitions to make your videos more exciting and keep people watching (and hopefully rewatching) until the end.
1. Use a tripod or other stabilization device to keep your camera still. This will help minimize shaking and ensure your videos look smooth.
2. Use TikTok’s optimal sizes, which are 1080 x 1920 with a 9:16 aspect ratio. You can resize videos using a free app like Veed or Kapwing.
3. Use good lighting. Natural light is always best, but if you need to use artificial light, make sure it’s bright and doesn’t create harsh shadows.
5. Post New Content When Your Audience Is Most Active
With engagement being such a critical factor in getting onto TikTok’s FYP, posting at the right time can make or break your video’s success.
How do you figure out when your followers are online and ready to engage?
With a free TikTok Pro Account. It’s similar to Instagram Analytics, and you can see:
- Video views over the last 7-28 days
- Profile views
- Follower growth
- Trending videos
- Gender/age demographics
- Your international audience
- When your followers are online
Basically, everything you need to tailor your TikTok content to prospects in your niche. A Pro account also gives you access to a WorkSpace and tools to help grow your followers.
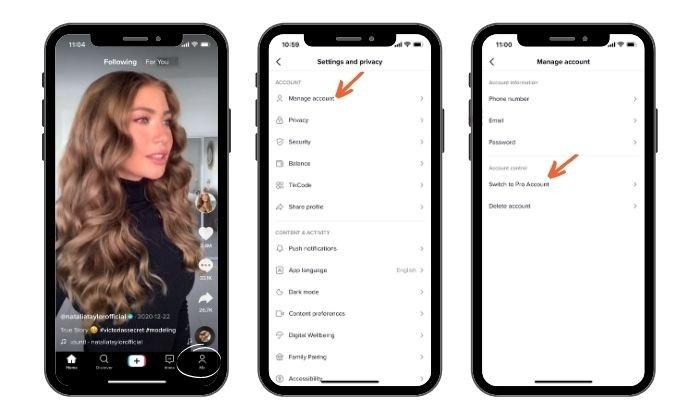
To switch to a TikTok Pro account, do the following:
- Open the TikTok app.
- Tap the “Me” icon at the bottom of the screen.
- Tap the three dots in the top left corner.
- Tap “Manage Account.”
- Tap “Switch to Pro account.”
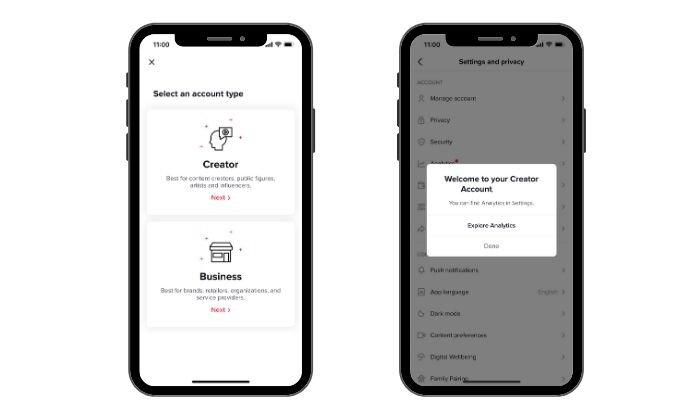
- Select “Creator” or “Business,” and you’re done!
6. Add Trending Sounds and Music to Your Videos
Think of music and sounds on TikTok like hashtags. You can use trending audio clips to boost your discoverability and get a bump in likes, comments, and views.
How do you find popular sounds to use in your videos?
You’ll need to put on your stealth hat to uncover what’s getting the most traction. Here are three ways to find trending music:
Sounds in the Video Editor
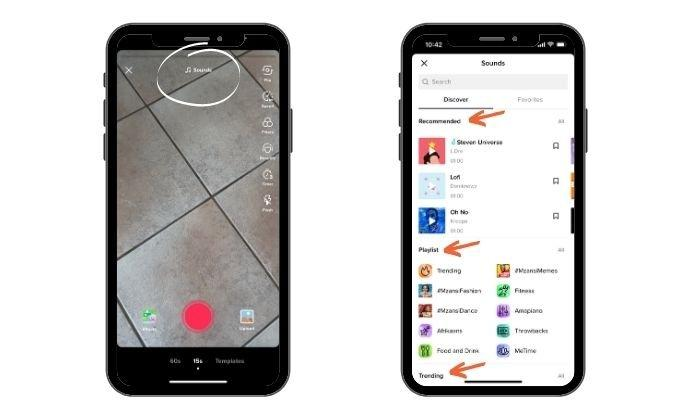
When creating a video, tap the “Sounds” button at the top of the screen. A new page will load, and you’ll see a “Discover” page.
Here, you can view recommended sounds for you to use and a “Playlist” section featuring viral clips, trending sounds, and TikTok music charts. You can also explore the “Trending” page to see what’s currently trending in different categories like “fitness” or “food and drink.”
Scroll through the sounds and add what you like to your Favorites folder to use for later.
Save Sounds to Your Favorites
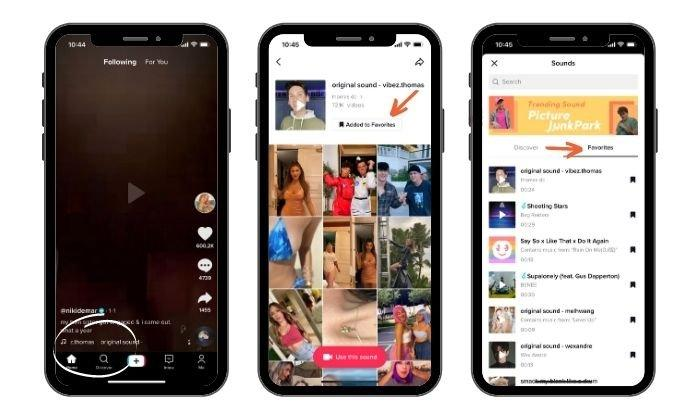
When you’re swiping through TikTok and come across a sound you want to use for a video, add it to your Favorites folder.
The feature collects your clips in one handy spot, and you don’t need to waste time trying to remember the name of a sound.
If you like a sound and want to save it, tap the sound name under the username. An audio page will load where you can see a list of all the other videos using it and a button to add the clip to your Favorites.
Use Sounds Your Followers Are Listening to on TikTok
Once you’ve switched to a TikTok Pro account and hit 100 followers, you’ll get access to another juicy analytics feature.
Under the “Followers” tab, you’ll see a list of sounds your followers have watched in the last seven days.
It helps reduce research time and shortlist sounds for your next video.
Use TikTok Stories
While they’re not a firm feature yet, TikTok has been trialing Stories. After an initial pilot in Brazil, U.S. users are starting to see notifications about the new app.
TikTok Stories appear for 24 hours before disappearing from feeds and have a blue circle next to them. Users can find stories by going to your TikTok FYP. Posting videos works much the same way as regular content. You just:
- Open TikTok’s posting tool and choose the ‘post’ button’
- Create some content
- Choose the ‘Story’ button. Then the TikTok automatically posts it to the For You feed
- Look at other users’ profiles and look for video posts.
Be Unique To Get Your TikTok On The FYP
It may seem like a good idea to copy popular ideas, but if you want to stand out, one of the best ways to go about it is by creating unique content.
Use the sounds and effects that others are using as inspiration, and see if you can take it in a different direction.
You can also get creative with your editing techniques and use filters and effects to add an extra layer of creativity to your videos.
Just one more tip before rounding off this section: stay active and engaged with your followers, liking and commenting on their videos as often as possible.
FAQs
What is FYP in TikTok?
FYP on TikTok is an abbreviation of ‘For You Page.’
How can I use hashtags to get on Tiktok's FYP?
Choose popular hashtags that are trending and relevant to your topic. Also include #fyp and #foryou (even though TikTok has not confirmed this guarantees a spot on the FYP.
How long are videos on TikTok's FYP?
Most popular TikTok FYP videos are 60 seconds or less.
What TikTok FYP captions should I use?
Captions on your TikTok videos should be short, include related hashtags, and encourage engagement (likes, comments, and shares) from other TikTok users.
What time should I post a video, so it appears on TikTok's FYP?
After you get 100 followers, look at your free TikTok pro account to see when users that like your videos are usually online. Try to publish a video when people are most active.
According to research from Later, Monday to Friday at 1 PM is the optimal time for posting. However, there are plenty of variables, such as time zones and niches, so that’s not guaranteed.
If it’s engagement you’re after, Later’s research also found that Thursdays and Fridays get the most attention.
What sounds will help me get on TikTok's FYP?
Effects are another factor in how to get your TikTok on the FYP. Try to use trending or popular sounds with your videos. While there is no official confirmed link between using trending sounds and being on the FYP, it usually helps increase popularity.
How long does it take to get on TikTok’s FYP?
There’s no firm timeline. Some find their content appears within 48 hours, while others wait weeks for their content to appear on the TikTok FYP.
How can I get my TikTok on the FYP?
Remember the basics. Use hashtags, short content, and viral sounds/images. Post at the optimum times and always maintain quality.
Conclusion
These tips are good starting points to get on the FYP. However, I’m not making any guarantees.
While these tips can significantly improve your chances, multiple factors can influence whether TikTok features your content in users’ feeds.
There’s more to TikTok than stardom, hashtags, and trending sounds. If you’re not creating memorable, worthwhile, and shareable content for your audience, there’s less chance TikTok will pick it up and share it.
How do you plan to use TikTok in your social media strategy?
Are You Using Google Ads? Try Our FREE Ads Grader!
Stop wasting money and unlock the hidden potential of your advertising.
- Discover the power of intentional advertising.
- Reach your ideal target audience.
- Maximize ad spend efficiency.