
In soccer, the ref holds up a red card when he or she notices a penalty. With Google, the penalty for duplicate content can completely destroy your SEO strategy.
Much of your marketing success revolves around your SEO strategy.
If you rise through the rankings, then your website and business will benefit from traffic, leads, and conversions.
If you don’t, then you either look at other marketing methods or try harder.
But, of course, you’re not alone in your desire to land in the top ten results of Google.
Those top spots represent a wealth of revenue for your business. So you know they’re highly competitive.
Which means that you need to leverage every SEO signal that you can.
And you know you don’t want a penalty. In sports, you might just have to sit out for a few minutes. But in business, penalties can screw up your chances of snagging customers.
Organic search traffic is far more common than paid search, and Google is at the top of the search engine pack.

In other words, if you really want to benefit from SEO, then focus your efforts on Google.
Unfortunately, focusing on Google isn’t enough to automatically surge your rankings.
Remember, almost every marketer with just a single grain of SEO knowledge is trying to increase their rankings.
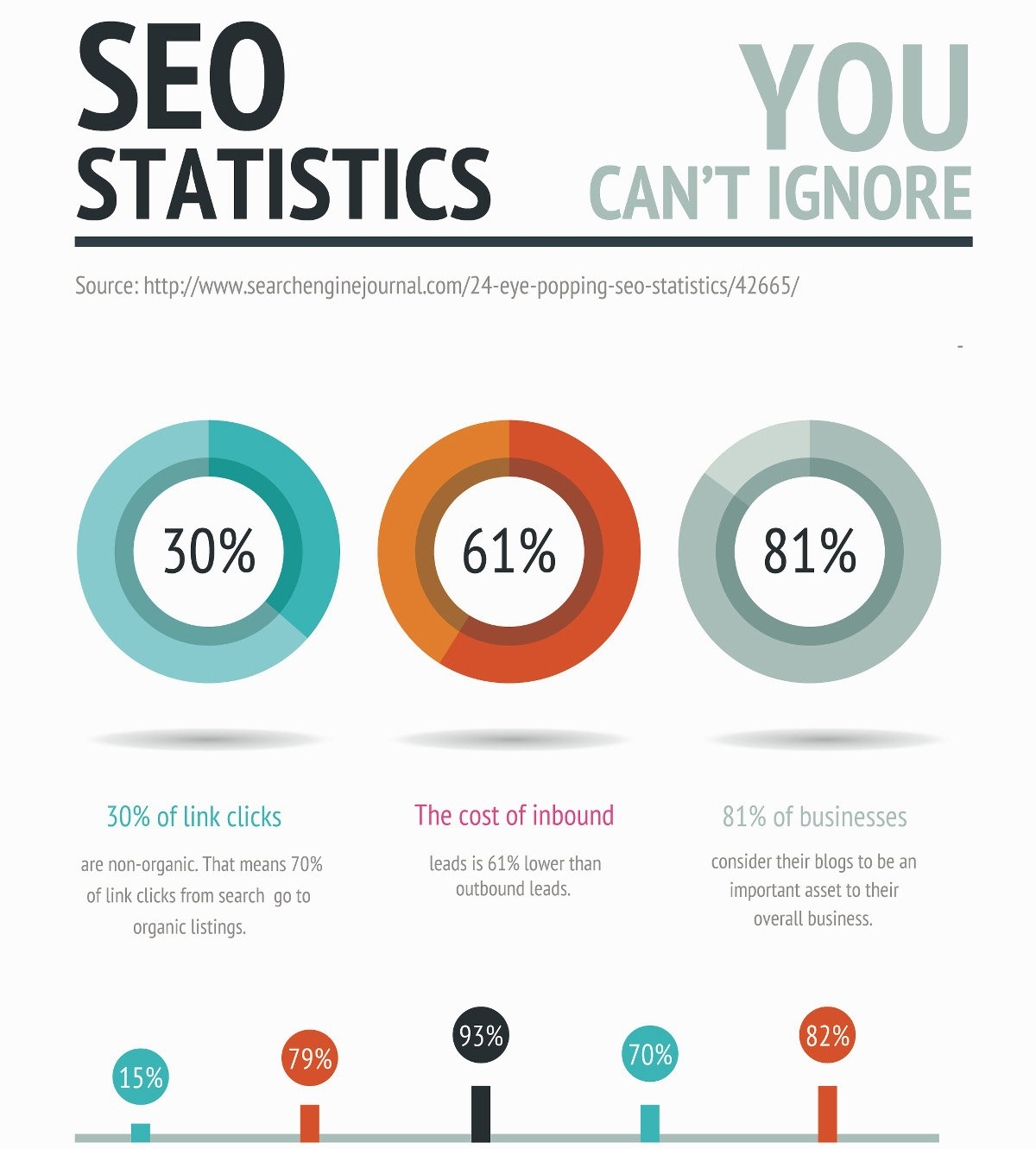
In fact, 78% of B2B marketers practice SEO regularly as a marketing strategy.
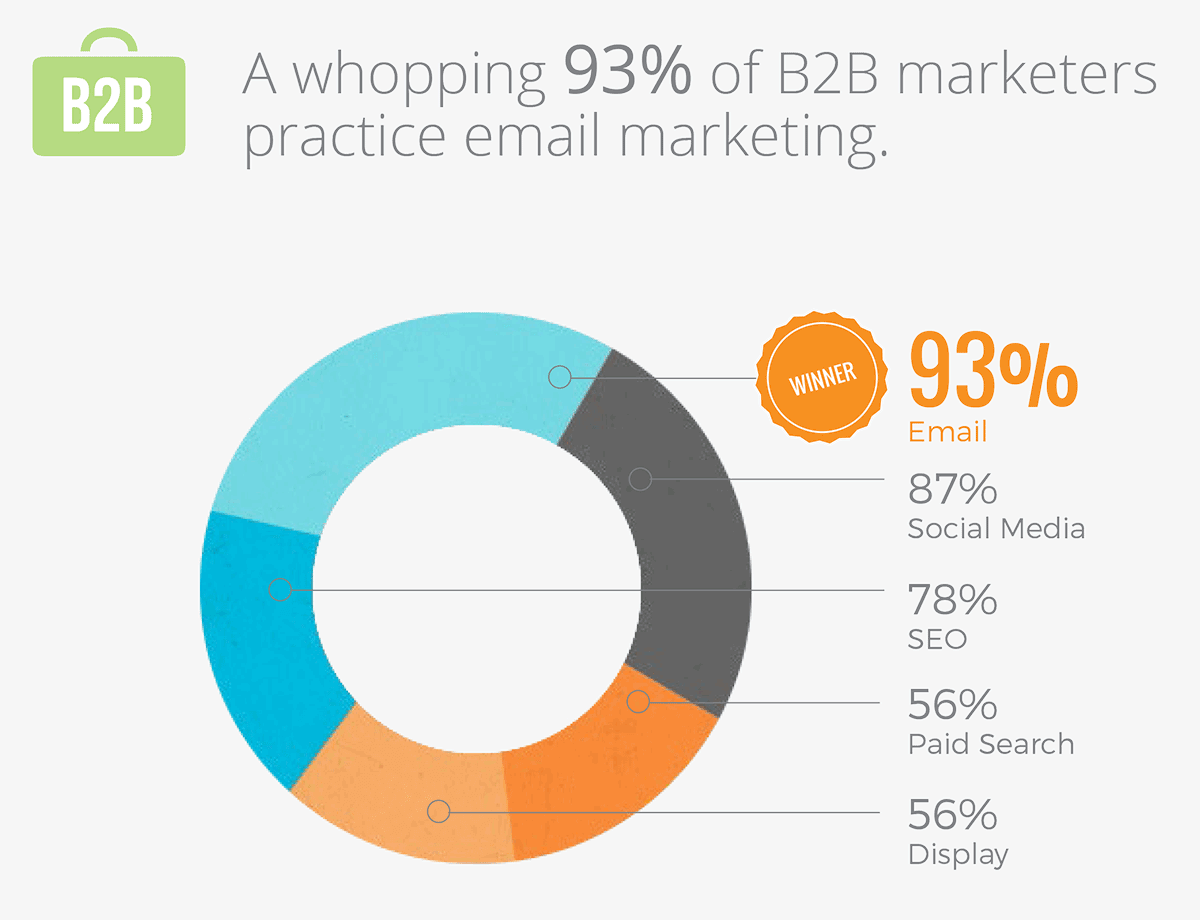
That makes sense when you think about it. The benefits of SEO are well-known and far spread.
Every marketer is trying to get their slice of the pie. Including yourself.
That means you have to be smarter, faster, and better than them to win.
Because that pie includes 61% cheaper leads and 70% of link clicks.
The last thing you want is to fall behind. You don’t want every other website in your industry to storm ahead while you lag in the wings.
Then, all of your competition wins the SEO potential — and you lose.
That’s not a recipe for success.
What does all of this have to do with duplicate content, though?
Well, duplicate content can hurt your rankings if you ignore it, and benefit your rankings if you fix it.
In fact, duplicate content might just be your ticket to the top of the SERPs.
What is duplicate content?
Maybe you’ve heard your friends talk about duplicate content.
Or maybe this article is the first time you’ve ever heard of it.
Most likely, though, you’ve heard the term but are still a bit confused. That’s okay. I was a little confused when I first learned about duplicate content several years back.
So bear with me and I’ll help you understand what duplicate content is and why it even matters.
At its heart, duplicate content is exactly what it sounds like.
It’s a duplicate page of an already existing page. And it confuses the heck out of search engines.
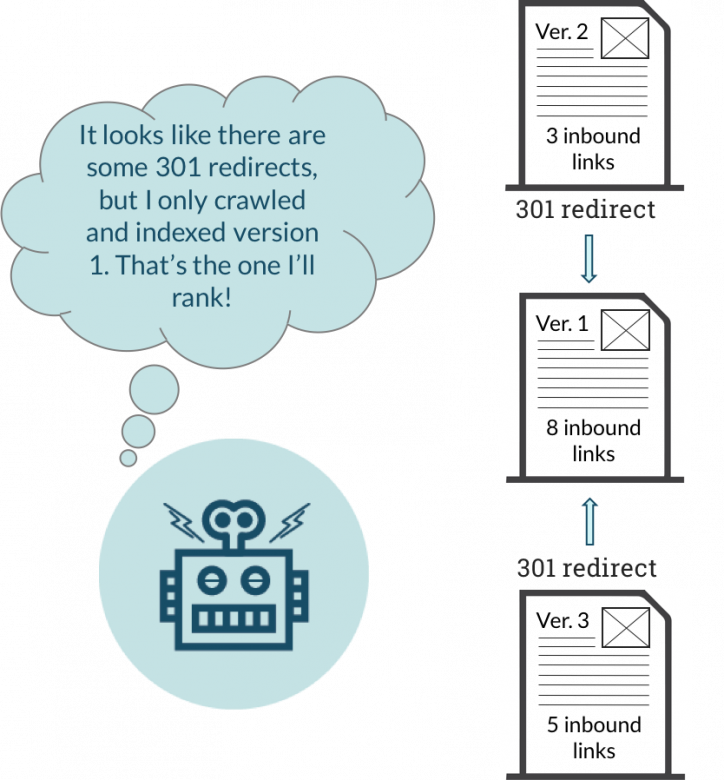
When a search engine sees several pages with duplicate content, it has to decide which one to rank.
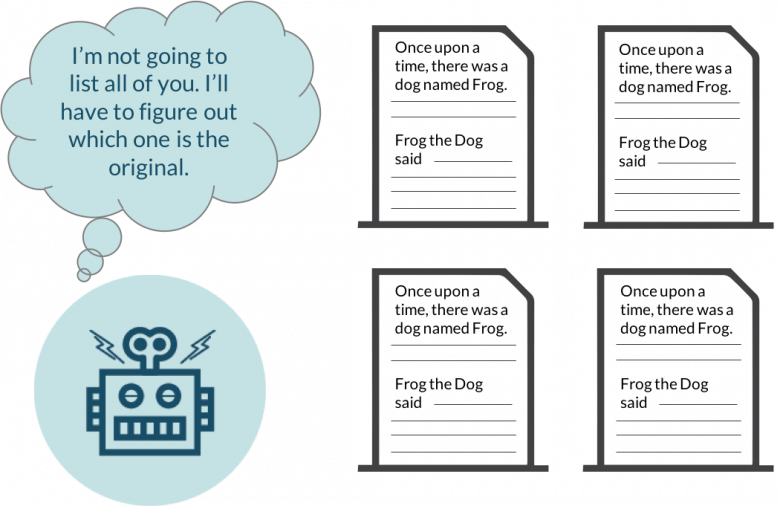
Naturally, you don’t want it to choose wrong.
Each duplicate piece of content has a slightly different URL. And even though you might see the same thing, Google and other search engines see several different pages.
Because of that, they have different rankings, SEO juice, and even page authority.
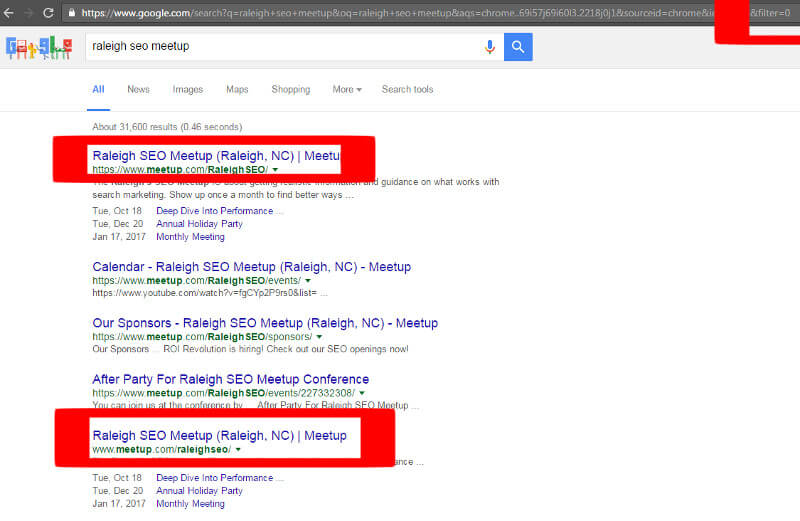
Not only does that look messy, but it can actually hurt the SEO of the page that you want to rank.
Sure, you might think that falling into several positions in the SERP benefits you, but does it really?
What if, for instance, you could combine the SEO juice of those two pages to rank one page even higher?
That would be pretty great, right?
Well, later in this article, I’m going to show you how to do that.
In terms of exactly what duplicate content is, here’s what Google has to say:
“Duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content or are appreciably similar. Mostly, this is not deceptive in origin.”
And they are definitely right about the lack of deception.
You’re not trying to deceive anyone with duplicate content. You probably didn’t even know you might have duplicate content on your website.
Often, you don’t create it intentionally, but it sort of creates itself.
If you want to check your domain for duplicate content, you can use this tool to do so.
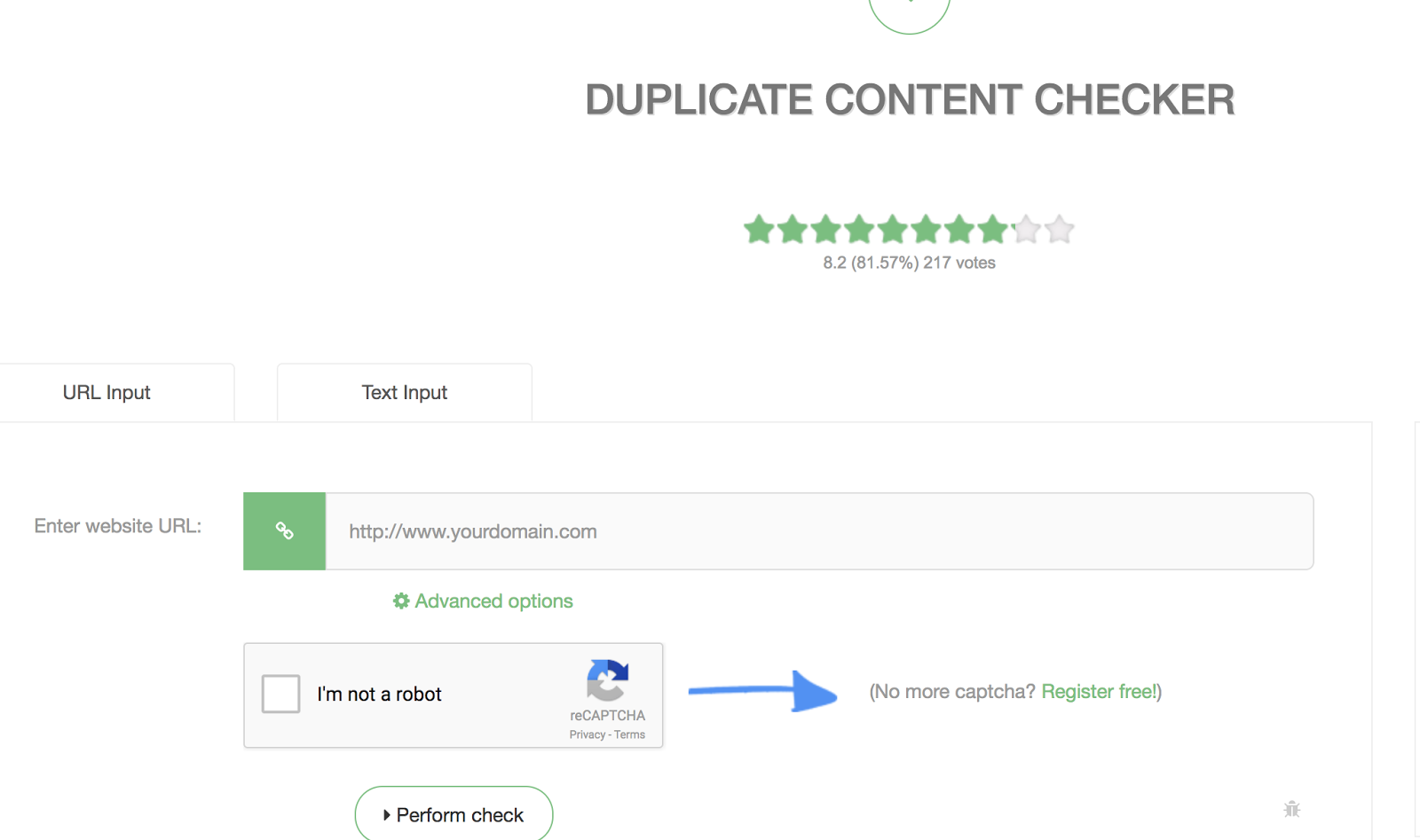
Just type in the URL you want to check and click “Perform check.”
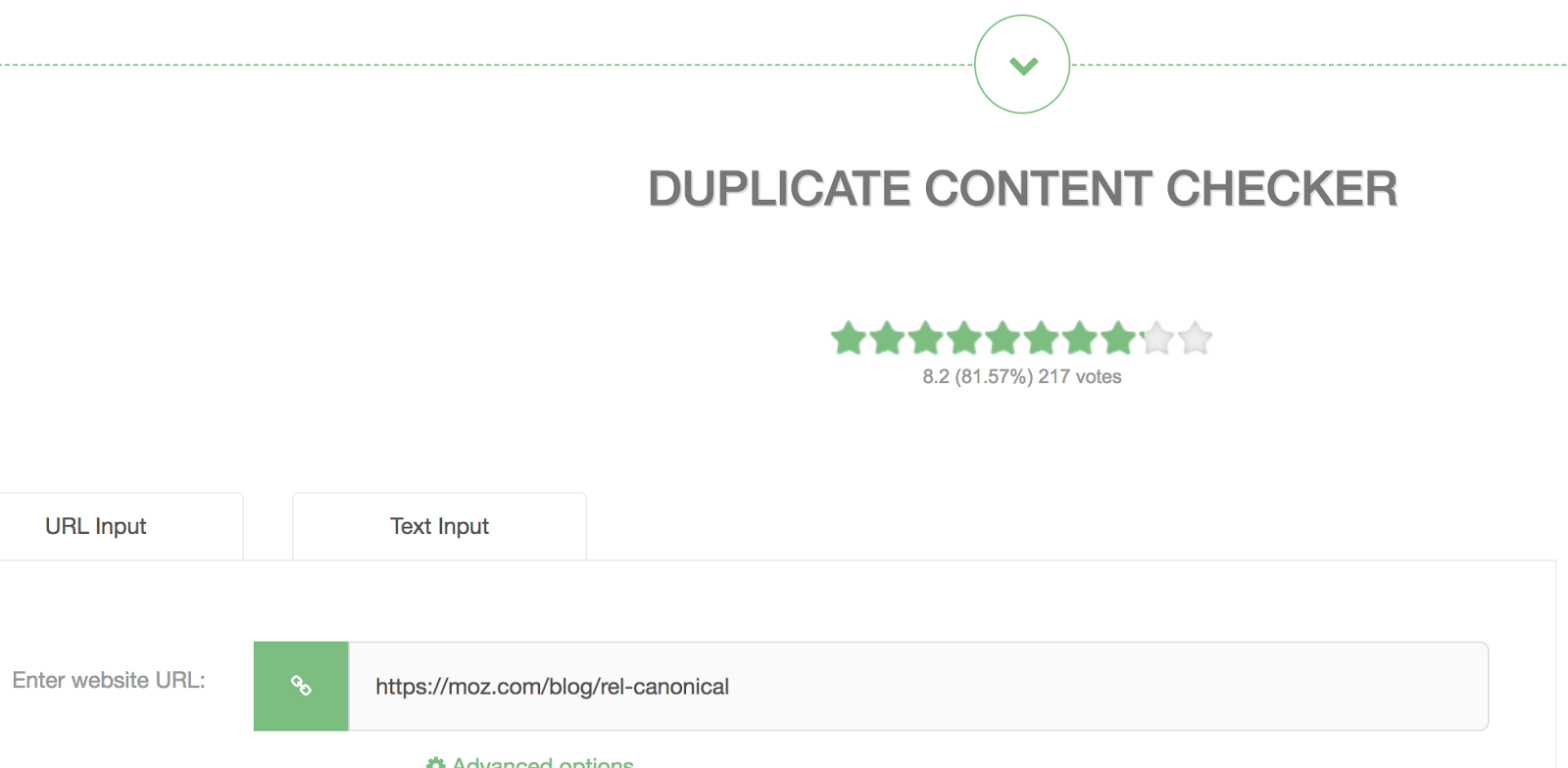
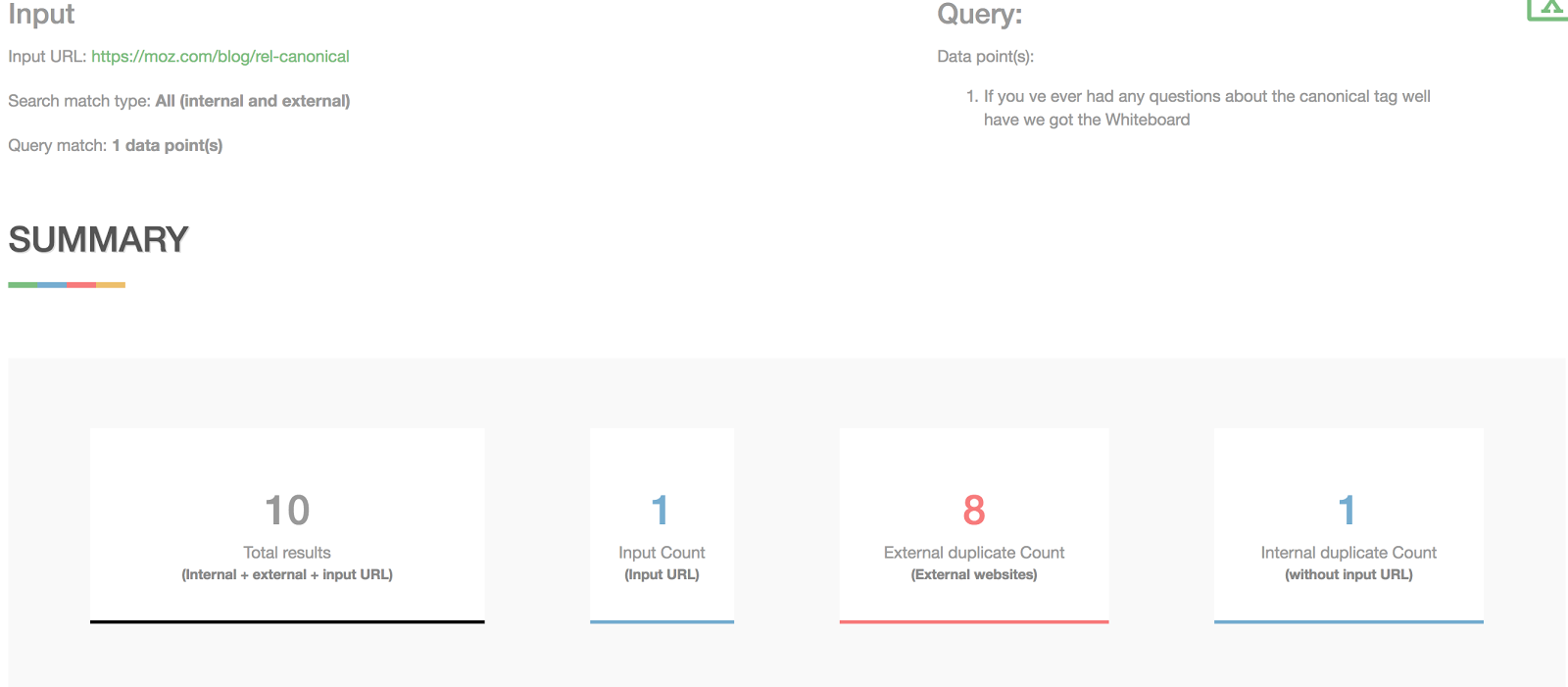
Then, the next page will show you how many duplicate pages there are of the URL you typed in.
As you can see, there are currently eight duplicate pieces of content on the Internet for the URL I typed in.
Now that you understand what duplicate content is and how you can find it on your own website, let’s talk about why it exists and what makes it appear.
Why does it appear?
Perhaps the most confusing part about duplicate content is why it shows up in the first place.
Most of the time, you didn’t intentionally try to create a copy of one of your already existing pages.
And yet, many websites have duplicate content.
So what creates it and where does it come from?
Here I’m going to show you a few causes of pesky duplicate content.
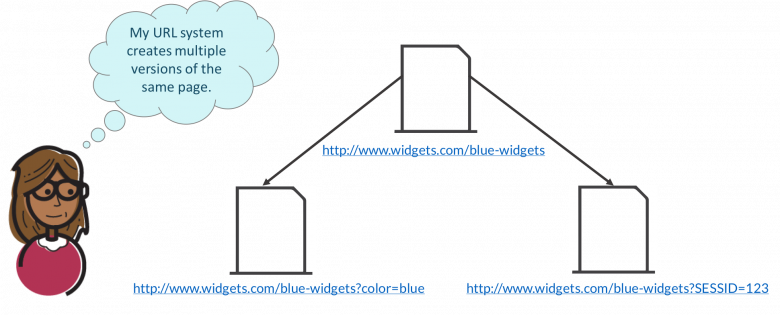
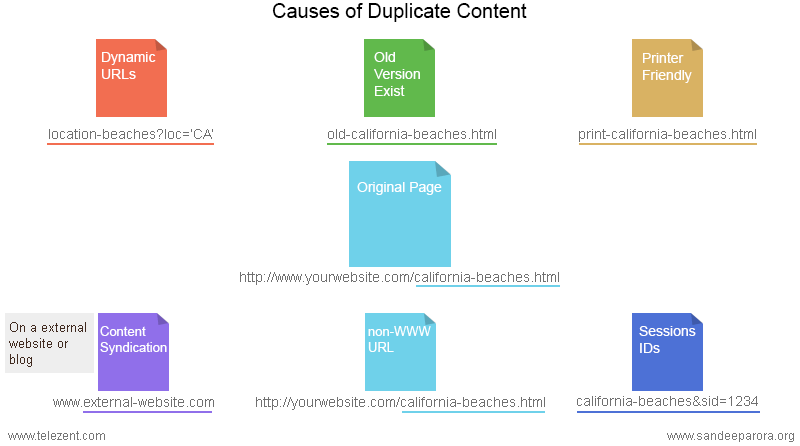
The first way that duplicate content shows up is when a website uses a URL system that creates multiple versions of the same page.
The page looks identical to every variation of it, but the URL is slightly different.
Kind of like this, for example.
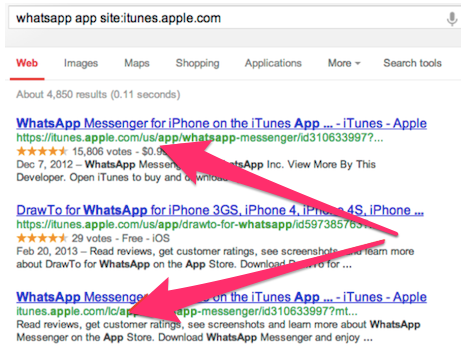
Another example of this happening is when you have one page URL that is HTTPS and one that isn’t.
Those pages are no longer the same pages, but duplicates of each other.
That looks like this.
Another way that you can unintentionally create duplicate content is when you publish a print or HTML version of an already existing page.
That’s great for letting people print out your content, but not so much for your SEO and your avoidance of duplicate content.

Of course, those are only a few ways that you or your system creates duplicate content.
There are lots of different ways that this happens, though.
Dynamic URLs, old and forgotten versions of a page, content syndication, and session IDs are a few more of the reasons that these duplicate content pages have found their way into the digital world.
Hopefully, now, you have a decent idea of what duplicate content is and what creates it.
But now we turn our attention to one of the most important questions about duplicate content.
Why does it cause a problem and how big of a problem is it?
Why does it cause a problem?
You might not know this. But yes, duplicate content causes a problem.
Believe it or not, having duplicate content on your website can hurt your SEO rankings.
Not directly, though. Google has actually said that duplicate content doesn’t outright hurt a website’s rankings. But it does hurt your rankings indirectly.
Let me explain.
Imagine for a moment that you have two pages with the same content on them. One has the primary URL, and the other is the duplicate.
Now, as would be the case, both pages have their own SEO juice. Since they have different URLs, they have received different backlinks and thus different page authority scores.
In that case, you have two options.
Leave each one alone to rank by itself or combine their ranking signals.
The latter is almost always the better option, and the former will almost always hurt your overall rankings for that page.
Just consider that 50% of websites have duplicate content issues that are harming their SEO.

The reason that duplicate content hurts your SEO is simple.
When you leave each page alone to rank apart from its duplicate, then it’s sort of like sending half of your army off to fight one war and the other half to fight another war.
Instead, you could combine their forces and be better off for it.
If, for example, one page is a 3 on a scale from 1 to 10 and the duplicate is a 4, then combining them would be a 7.
In other words, the whole is far more powerful than the individual parts.
If you leave the decision of which pages to rank and which to ignore up to Google, then it might make the wrong decision.

Ideally, you want to tell Google which version of the page to prioritize and then send all of the SEO juice from the duplicate pages to that canonical page.
As with most things in life, though, there are a few different ways to do that.
Here are the three ways I recommend.
1. The rel=canonical tag
In most cases, the rel=canonical tag is the best way to transfer SEO juice from a duplicate page to another page.
Basically, this is an HTML tag that you can add to a certain page, which then tells search engines that this page is the one that you want Google to index.
Then, when Google finds any duplicates of the page, it will attribute all of the SEO juice from those duplicates to the canonical page.
Which means that your rankings increase and the page that actually matters wins.
It’s similar to a 301 redirect, but easier to implement.
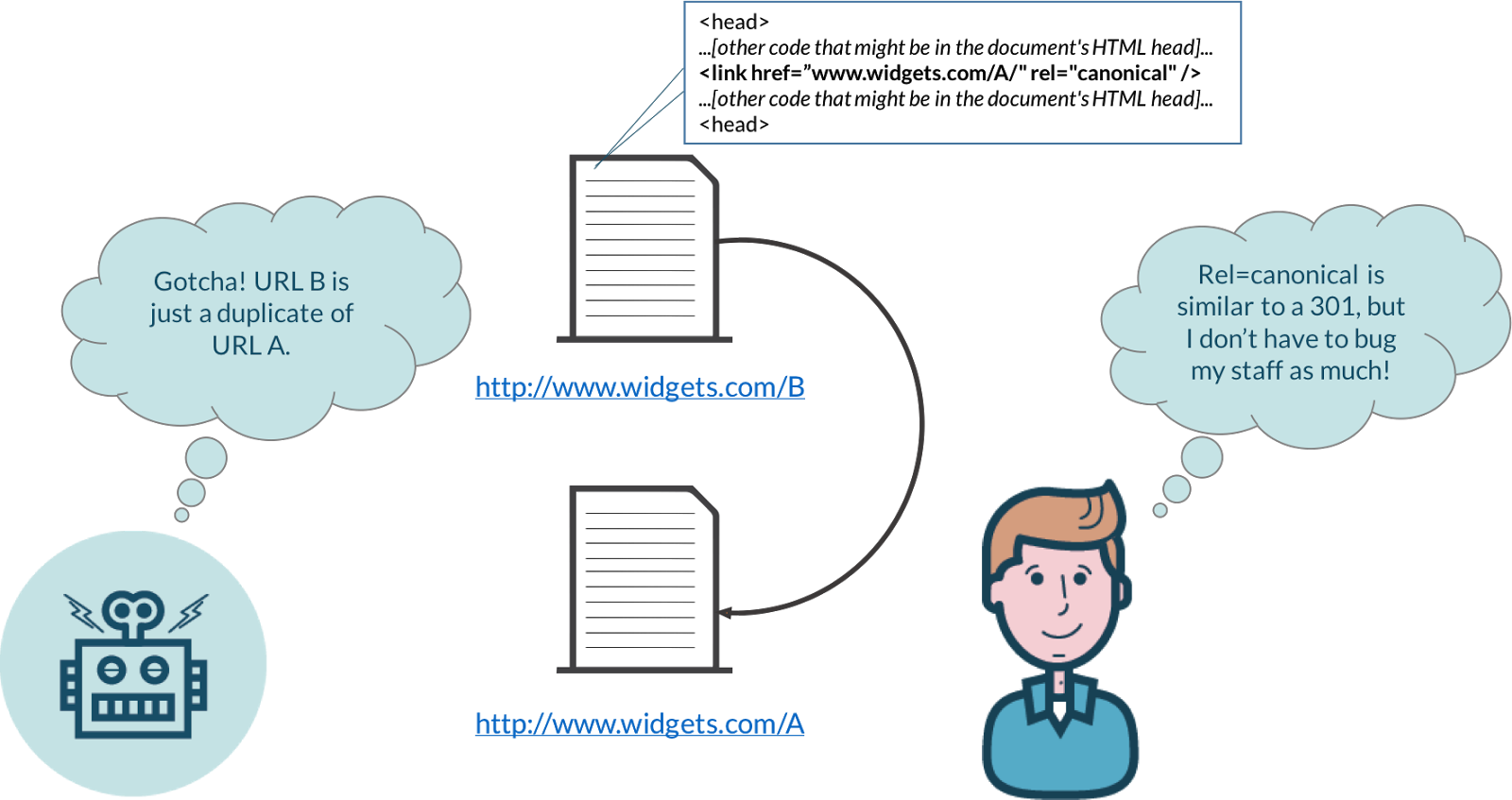
Plus, when you do this, the old page doesn’t go away. Google simply recognizes it for what it is: a duplicate of another page.
Sometimes, you don’t want the old duplicate to go away. You just want to put all of the SEO juice in one place.
If, for example, you have an HTML, printable version of a page, you don’t want to delete that duplicate altogether.
But you also don’t want it to rank.
For that, the rel=canonical tag is a great solution.
Here’s what it looks like in the code of your website.

And once more.
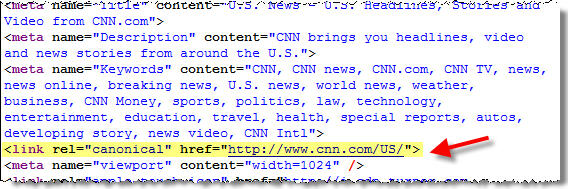
If you’re using a WordPress website, then adding this tag is quite simple.
First of all, there are several plugins that will allow you to do it with ease. You can browse through some of those here.
If you want to do it manually for your primary domain, however, then simply add this code to the head of your theme template.

Just make sure to replace the “bybe.net” portion with your own URL.
Then, Google will know which page to send all of that duplicate SEO juice to, and your rankings will immediately benefit.
2. 301 redirect
Sometimes, you don’t want the duplicate of your web page to stick around.
Maybe you only want the primary version of the page to exist, and those duplicates are just cluttering your online space and your visitor’s vibe.
Still, you probably want the primary page to benefit from the SEO juice of its duplicates.
Is that possible, though? To kill the duplicate pages and still have them raise the SEO of the primary page?
Yes. Yes, it is.
And it’s possible because of 301 redirects.
These puppies allow you to tell search engines that whenever someone tries to visit page A, you want them to send those people to page B instead.
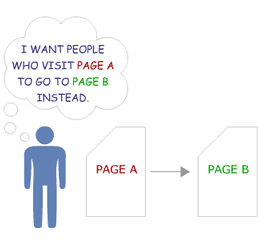
However, a 301 redirect still doesn’t delete page A. It simply redirects any visitors to page B instead.
In other words, no one can ever see page A, but it’s still helping page B to rank better.
Since it isn’t deleted, all of its SEO juice automatically gets attributed to the page that it’s redirecting to.
And search engines know exactly what to do when you 301 redirect a page.
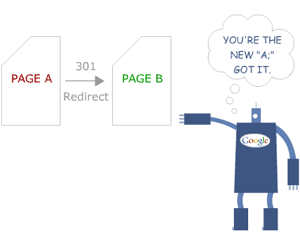
Be careful of using a 302 redirect, however. Those are only temporary, whereas 301 redirects are permanent.
Here’s how a search engine computes a 301 redirect.
If you decide that a 301 redirect is the right choice for your duplicate content situation, then here’s a list of different WordPress plugins you can use to create the redirect.
On WordPress, a plugin is your safest and easiest bet.
3. Set passive parameters in Google Search Console
Unfortunately, sometimes you’re in a hurry.
While I don’t recommend using passive parameters for the long run, it can be a helpful short-term strategy.
When you set certain URLs as passive to Google, that tells Google’s crawl bot to basically ignore that URL.
Clearly, that can help remove duplicate content.
If you have several bizarre and cluttered results showing up within the SERPs, then you might just want to quickly remove some of those.
However, maybe your dev team is too busy to run through and add rel=canonical tags to hundreds of different pages and then point them in the right direction.
After all, that is a ton of work, and your dev team is already busy enough.
If you want to mark some pages as passive, then go to Google’s Search Console and click on URL Parameters on the left side of the screen.
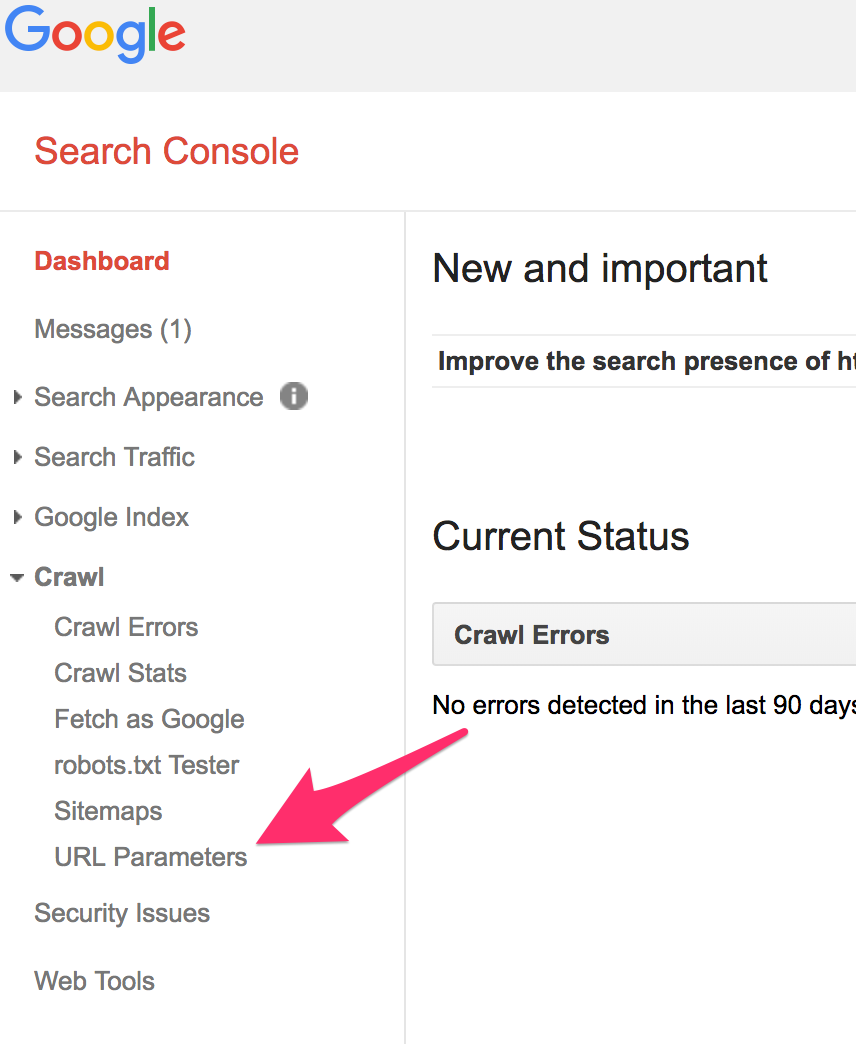
Then click “Add parameter.”

Enter the URL of the page you’d like to mark as passive and then select, “No: Doesn’t affect page content (ex: tracks usage).”
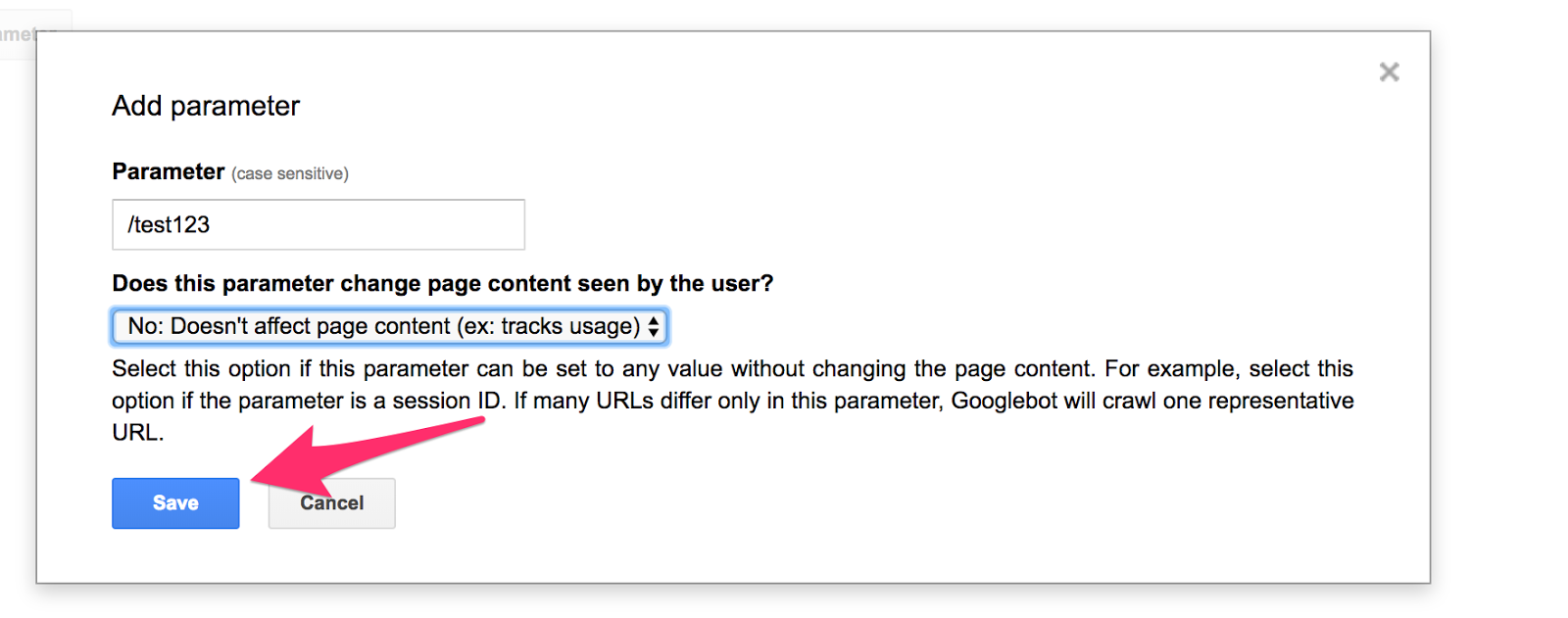
Click “Save,” and that URL will now be marked as passive in Google search results.
That means it can’t show up when people are searching for your website.
That can be helpful when your dev team is busy, or when you are unconcerned about the potential SEO benefits of linking that page to another canonical URL.
That is, of course, the downfall to this strategy.
The URL that you are keeping around doesn’t receive any SEO benefits from the duplicates that currently exist.
However, that might not be such a big problem if the duplicates you’re removing from Google’s eyes are new or have very little page authority.
In that case, this might be one of the better solutions to remove duplicate content from your domain.
If, however, this is only a temporary solution to help a busy dev team, then make sure to go back and use the rel=canonical tag or 301 redirect when you have time to do so.
Conclusion
Whew. That was a lot.
But now you understand what duplicate content is, why it appears, why it’s a problem, and even how you can remove it safely.
Because here’s what you don’t want to happen.
You don’t want all of that duplicate content hurting your SEO, and you definitely don’t want to remove it incorrectly and hurt your SEO even more.
Keep in mind the three strategies I mentioned here when removing duplicate content and choose the one that best fits your current needs.
The rel=canonical tag is the best for almost all circumstances, but it can take a decent amount of time if you have a lot of pages to fix.
The 301 redirect is great if you want to make it impossible for visitors to view the duplicate content but still have the primary page benefit from the SEO of the duplicate.
Remember, though, that this solution will take you the longest of all your options.
And passive parameters can be a great short-term solution if you don’t currently have the time to set up 301 redirects or rel=canonical tags.
One thing’s for sure, though.
If you don’t deal with duplicate content on your website, it can hurt your rankings and thus your business.
Don’t let that happen.
What strategy do you use to remove duplicate content from your domain?
Are You Using Google Ads? Try Our FREE Ads Grader!
Stop wasting money and unlock the hidden potential of your advertising.
- Discover the power of intentional advertising.
- Reach your ideal target audience.
- Maximize ad spend efficiency.