




Everyone is looking to get ahead when it comes to SEO.
But that can be hard when your competitors are putting out content that ranks better than yours.
There are a lot of reasons why their content ranks, of course. Maybe they have better domain authority than you do, or maybe they have a larger built-in audience.
That shouldn’t get you down, though.
There are ways that you can use their content to your advantage.
One of those ways is to use a content scraper (also known as a web scraper) to gain insights into what they’re doing so you can do it, too.
The only caveat is that you have to know how to use them correctly. Otherwise, you could be stuck with the wrong data.
Here’s what to know.
What is content scraping?
Content scrapers are automated programs that pull data from multiple websites.
Let’s say for a moment that you wanted to see what sort of titles your competitors were using on their blog posts to get the most clicks.
You could visit each website individually, scroll through archived blogs then copy and paste each title into a spreadsheet. That’s how most marketers do it.
But that’s a lot of work.
Some sites have hundreds or even thousands of archived blog posts you might have to sort through.
Instead, you can use a content scrapers to gather those titles for you, along with metadata descriptions and links, if needed (all factors that can influence SEO).
At this point, you might be wondering, “If this was so easy and perfect, why isn’t everyone doing it?”
Well, they probably are. Google actually scrapes your site to add content to its index.
That’s how your content ranks.
But there are also plenty of malicious scrapers out there who might steal your content and post it on their website in order to outrank you.
They might:
- Copy and republish content word-for-word (also known as plagiarism).
- Copy content from other sites with some minor modifications, publishing it as original.
- List other blog posts on their news feeds from other sources (consider it external linking done wrong).
Google doesn’t like any of these things, and they will penalize you for it.
I don’t want you to do any of these things either.
I don’t believe in stealing content in order to rank, especially since original content is so good for marketing.
What you can do is use scrapers as a “white hat” marketing tool.
In other words, you can pull just the data you need from websites without having to do the manual work, but not use that data to copy content.
You’re going to use the data to inform your marketing practices.
Here are a few ways you can use white hat content scrapers to boost your SEO.
1. Scrape organic keyword results
The best use for content scraping is keyword research.
This means finding out which keywords your competitors are ranking for, what metadata they use for their blog posts, and what type of PPC ads they’re running.
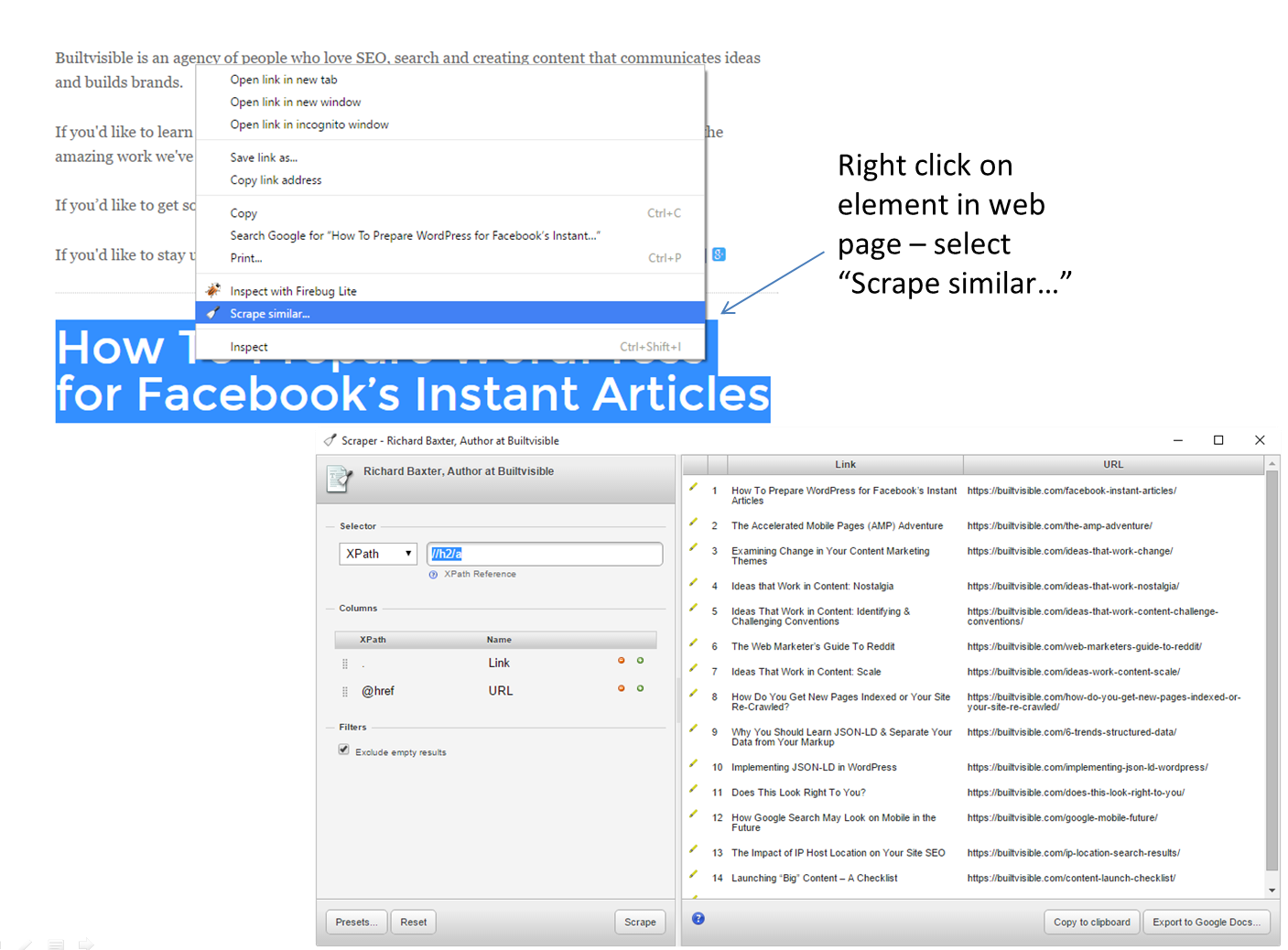
You can start with a simple content-scraping plugin like Scraper for Chrome.
But depending on what you want to do, a more robust tool might be better.
You can also build your own content scraper if you have the coding know-how.
The tool you choose will ultimately depend on how many websites you want to scrape.
If you want to know what hundreds of other sites in your industry are doing, then you need more than just a plugin.
To scrape for a list of competitive keywords, for example, a tool like SEMRush (technically a web scraper) is fast and easy.
But SEMRush won’t scrape every website because many sites use proxies to block scrapers.
If you need to expand your search to “unsearchable” sites, you can use a tool like ScrapeBox.
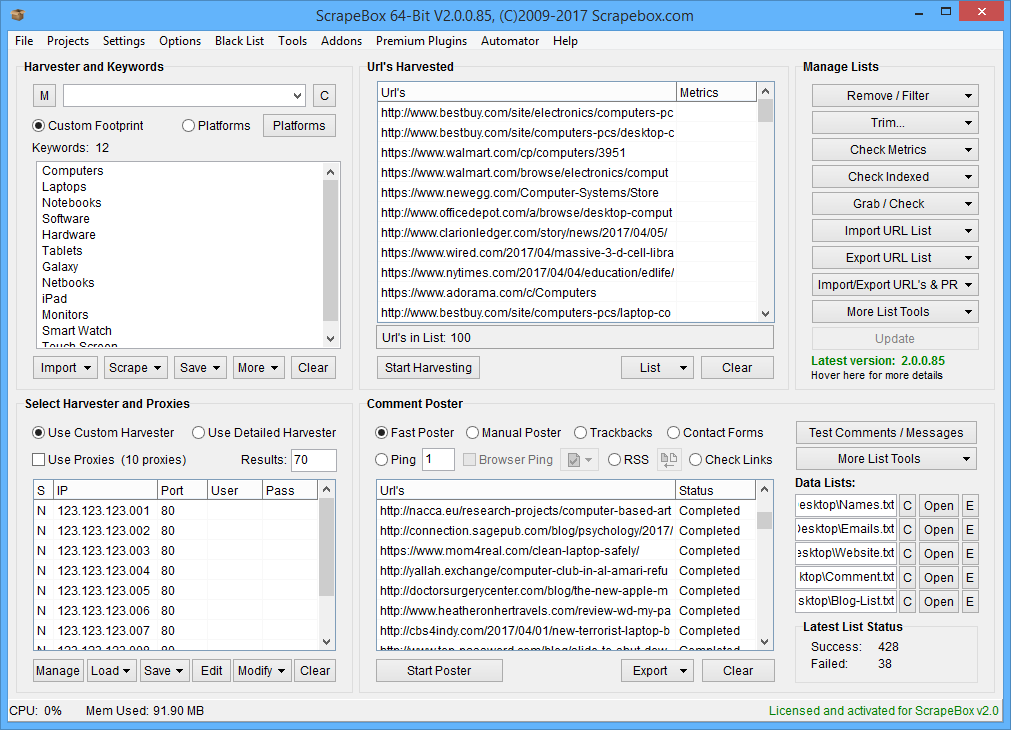
Scrapebox is a good alternative to SEMRush because it works on almost any site. It’s also pretty easy to use.
To use Scrapebox, drop a keyword (or keyword list) into ScrapeBox’s Keyword Scraper Tool.
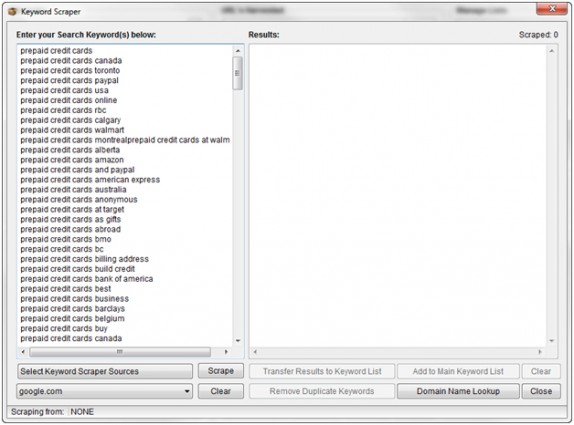
Then select your scrape sources and search engines.
You have a few options, including Google Suggest, YouTube Suggestions, and Google Product Search.
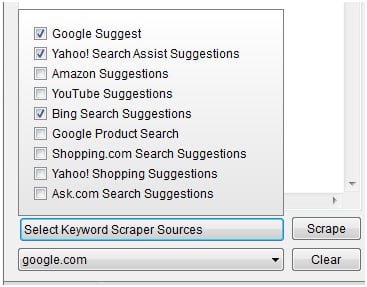
Once you have your chosen sites, click “Scrape.”
Depending on the sources you choose, it can take several minutes to generate a list.
But once it’s done you should have a much larger list of potential keywords available to you.
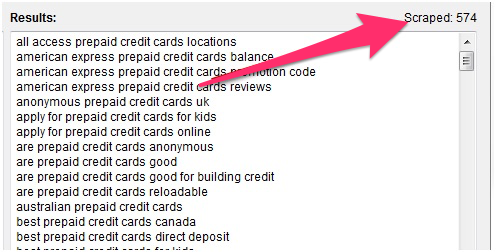
Just be sure to get rid of duplicates using the “Remove Duplicate Keywords” feature.
And there you have it!
No fuss, scalable keyword research from any site on the web.
2. Search Adword copy for inspiration
SEMRush might not be great for “unsearchable” sites but it’s still a helpful scraper for Adwords.
While some sites may block scrapers from using their keywords or searching their blog metadata, for example, Adwords are less likely to be blocked.
To find paid keywords go to SEMrush > Advertising Research > Positions and enter a domain.
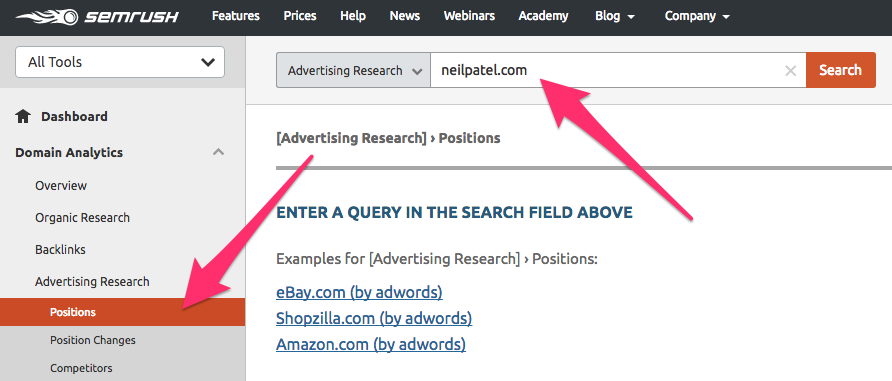
This will give you a list of keywords that domain purchased via AdWords.
By clicking on the arrows in the CPC column, you can sort the results in descending or ascending order by cost.
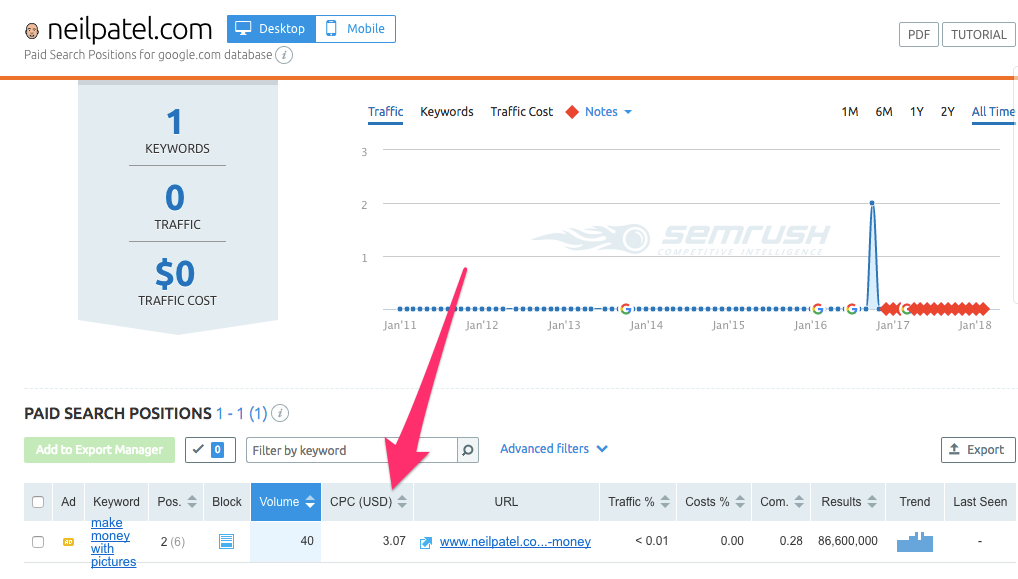
You can then export this data into a spreadsheet to keep track of your keywords.
If you have access to SEMRush, but you don’t like how the export feature organizes keywords, you can also use a plugin like SEOGadget for Excel.
It takes the data from SEMRush (or other scraper tools, like Moz) and automatically organizes it into Excel.
You can then scrape sites directly from Excel using different Excel formulas and functions.
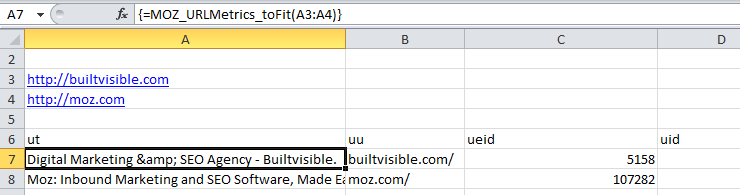
This can be really helpful if you’re the sort of person who doesn’t like using ten different tools just to do some preliminary keyword research.
You can set up the whole process in Excel and have fields auto-populated when you need them.
The plugin is also free, as long as you have an API key to a tool like SEMRush.
So if you’re already doing keyword research using scraper tools, this will save you a lot of time and energy in the process.
3. Find potential influencers with blog comments
I’ve written before about how blog comments can improve your SEO and help you connect with your audience.
That’s why I have comments enabled on my blog.
I also know that guest blogging is a great way to boost SEO, especially if you can find bigger influencers to write for you.
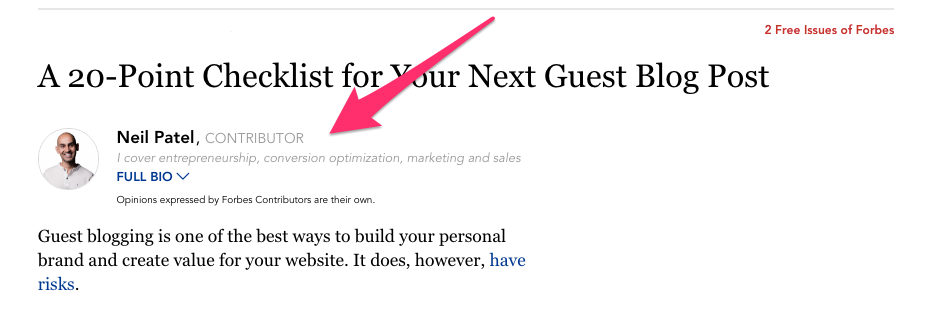
That’s a built-in audience right there, plus you’ll see a big boost to your traffic.
It’s not always easy to get those big name influencers to write for you. Many of them are busy, or may not guest post on anyone’s site, much less yours.
But you can always find people who might be willing to write for you — smaller influencers or lesser-known experts — by searching blog comments.
If you want “brand evangelists” for your own blog, you can scrape all of your own comments to find those who might be interested in guest posting.
This method doesn’t even involve your competitors.
The first thing you’ll want to do is find all the posts on your site related to a specific topic, and scrape the names and contact information of any commenters on those posts.
Once you have the names and contact information for your commenters, you can reach out and see if they would be interested in writing for you.
If you’re scraping your own site, you already have a connection point (they already commented on your post, so they know who you are), so it’s a warmer lead than a cold email.
You can also scrape competitor’s websites to find other influencers, but just remember that any contact you make will be totally cold.
Remember: Just because someone commented on a blog doesn’t mean they want solicitations, so be sure to approach carefully.
4. Use data feeds for guest blogging research
But what if you want to be the one guest posting?
Having your name and website linked to other blogs is a great way to boost your own site’s SEO, but it’s not always easy to become a guest poster.
You have to:
- Develop relationships with other sites.
Figure out how they produce their content (they might not tell you). - Come up with a successful pitch or two (or ten).
- Write a cold email that sells them on why you deserve to be a guest poster.
While ultimately worth it for the SEO boost, it can be a rigorous process depending on who you’re pitching.
Check out these rules for submitting to a site like Forbes, for example:

More than likely they’ll want someone to write for them who is already familiar with their content.
You don’t want to spend the time searching for and sorting through their entire blog feed to find articles that relate to your pitch, though.
That can be incredibly time-consuming.
So instead, use a content scraper to pull blog information from their RSS feed.
First, you want to find the RSS for their blog. Usually, it’s something like “domain.com/blog/feed” (not every site has an RSS feed like this, so this won’t work for everyone).
You can find mine here, for example. It looks something like this:
It’s just a bunch of raw data, though.
That’s where the scraper will come in handy. It will categorize that data into a list or spreadsheet of titles, authors, publishing dates, URL links, and so on.
This will let you sift through the data for relevant content.
You can then find posts similar to your pitch, or come up with topic ideas that might appeal to their audience.
It’s all for research purposes, of course, but it’s research that can land you a guest spot.
And if your pitch lands, it will be great for your own rankings.
5. Determine your best performing categories
While I would love to say that all of my blogs show up on Google’s first page SERPs, they don’t.
A lot of them do, but not all.
I do try to write content that at least stands a chance of showing up on the first page, though, which means I spend time reviewing my best performing posts.
I’ve found that it’s not just a specific title that makes some posts more shareable than others. Really, it’s the topic itself.
Some categories are simply more shareable for my audience than others.
When I look at my most shared posts, I can see a pattern:
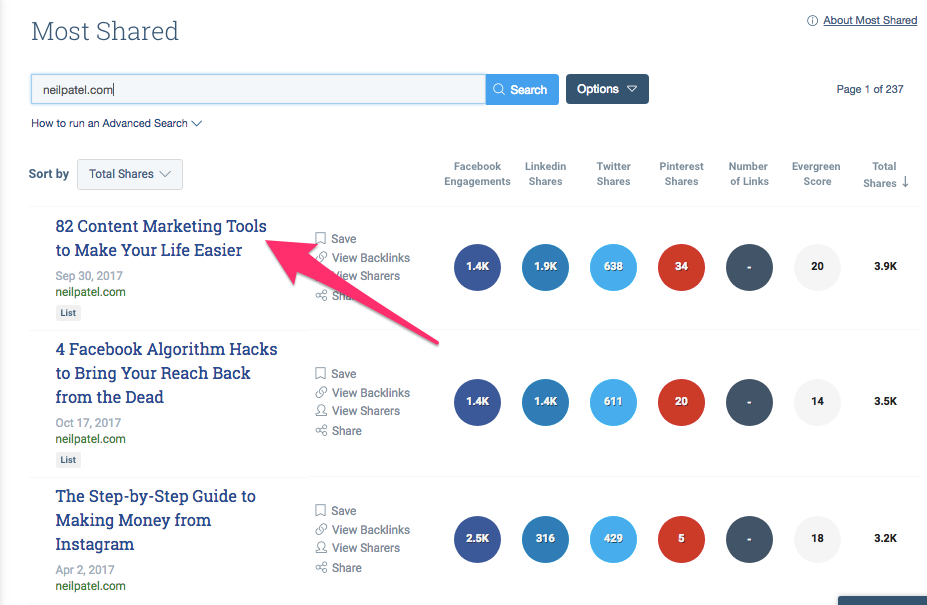
They tend to be about content marketing.
So I list that category near the top of my blog’s homepage.

My most popular topics tend to fall into a small number of categories in general.
I’ve written about other stuff, sure. But this is the stuff that people really want to read from me.
You can figure out which categories are doing well by using a content scraper like Ahrefs Site Explorer.
Type in the domain you want to search, click on “Top Content” and then export the results.
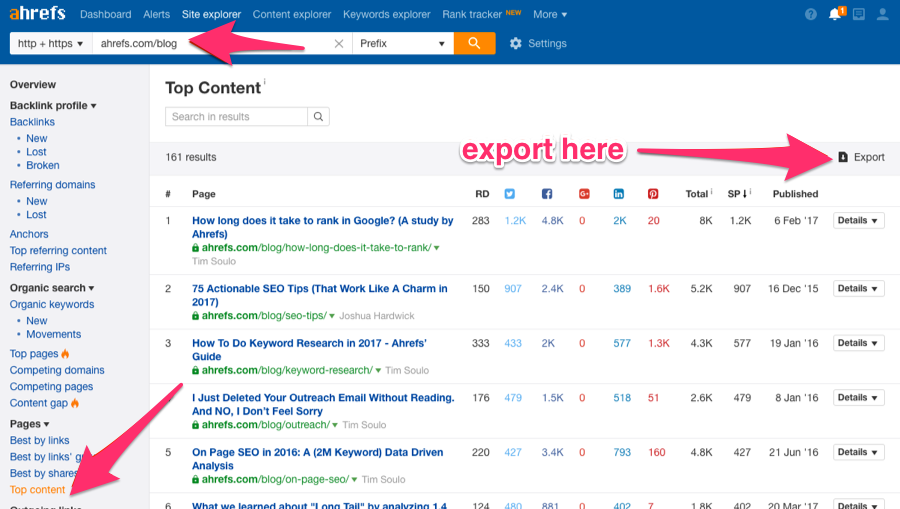
Your document should look something like this:
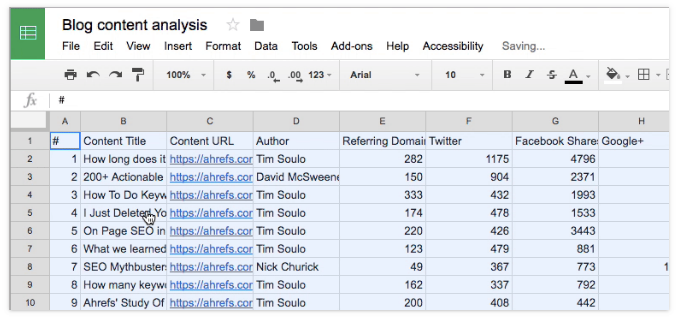
You can then find the most popular categories for each blog post by clicking on the individual links and running them through a web-scraping tool like Screaming Frog.
Screaming Frog will analyze the results and organize them based on specific metrics.
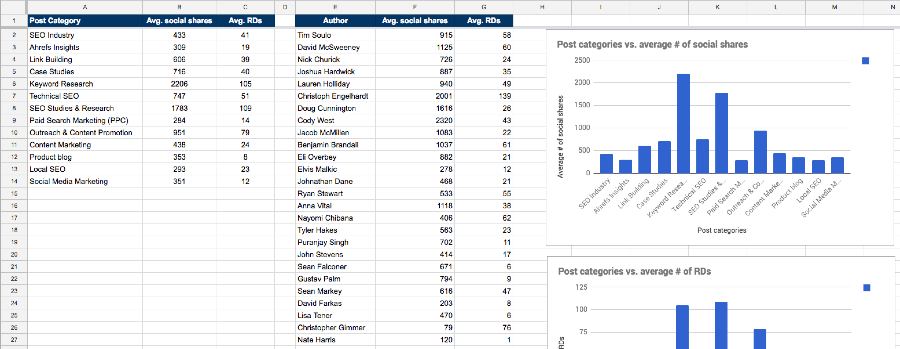
This will give you insight into which categories are the best performing for your audience.
You can also run this tool on competitor websites to see how they organize their content and what their audience finds most appealing.
It’s a great strategy if you’re looking to add categories or narrow down the topics of your blog.
I usually recommend doing this type of research at least once a year to make sure your content is still resonating with your audience.
6. Find content on forums to create backlinks
Most marketers are aware that building backlinks is an important part of SEO.
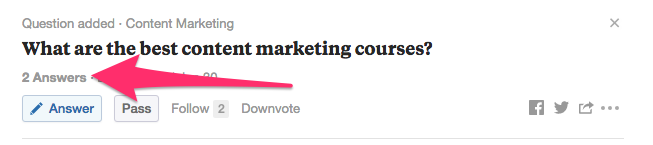
One of the best ways to build backlinks is by using forums like Quora and Reddit to find questions related to your business and then answer them, typically with a link back to your site.
Here’s an example of a subreddit for Content Marketing:
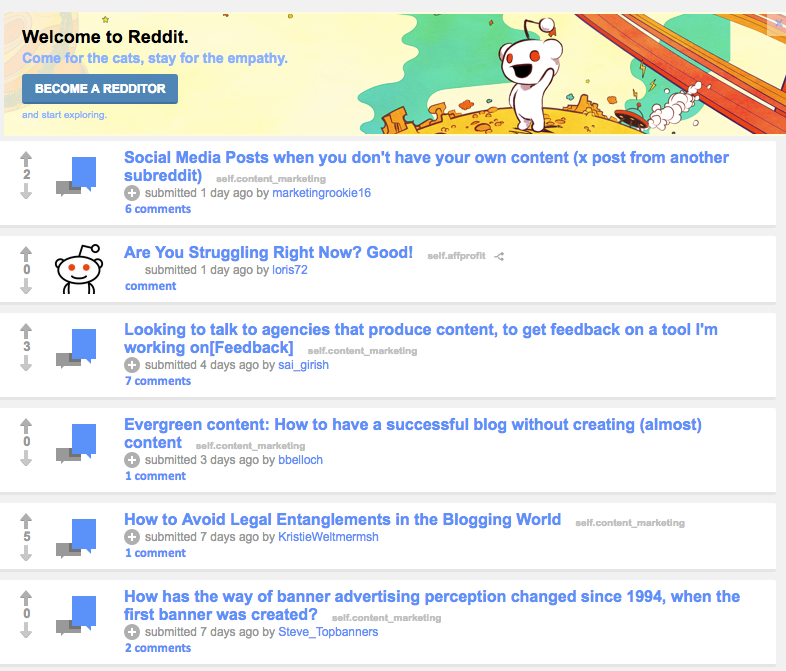
But all of this looks rather messy, right?
Well, Reddit actually makes it easy to scrape and organize data from their site.
They have an API (a web application) that is already set up for data collection. Many forums and websites have APIs that can help you scrape data legally.
You can access Reddit’s API through the GitHub Reddit wiki, their API documentation or the subreddit /r/redditdev.
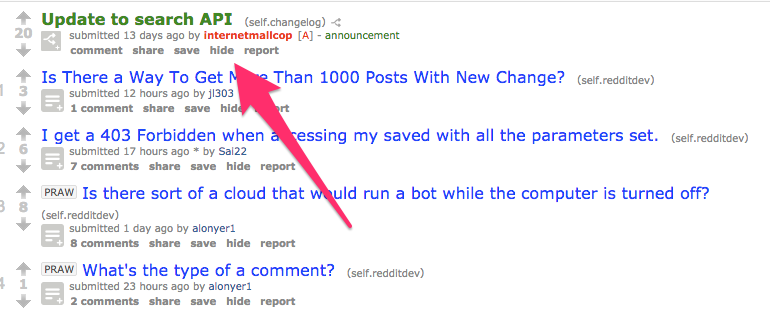
While this does take a little bit of technical know-how, it can help you sort through the chaos of forums that are often 100+ pages deep with content.
Unfortunately, Quora doesn’t allow scraping of their site for legal reasons.
So while you can get content from them with a scraper, it’s considered “black hat” scraping and you don’t really want to do it.
But I mention it because you can still search Quora for top questions using their search bar.
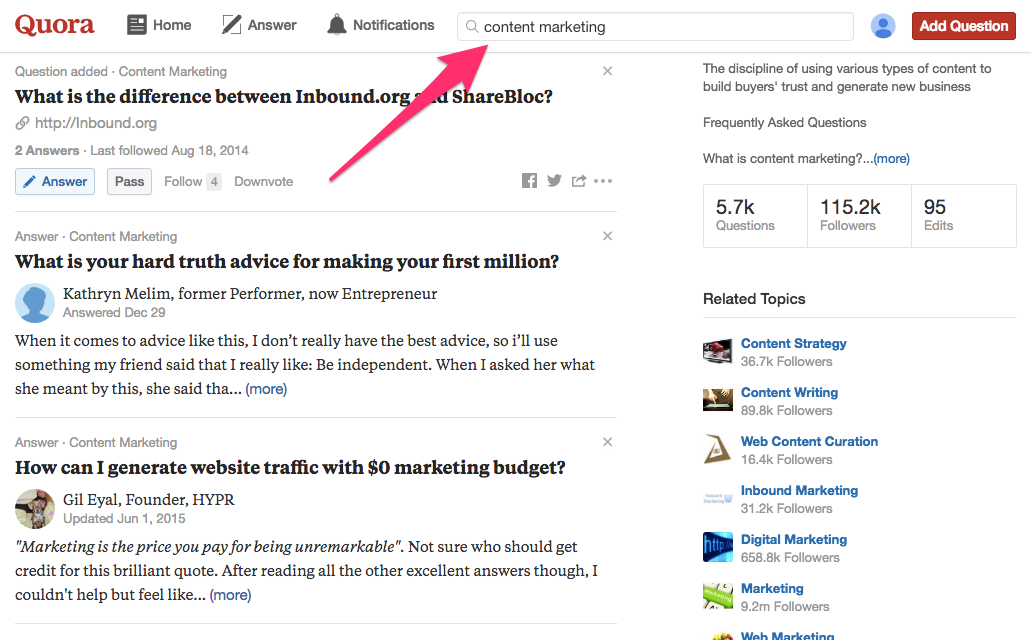
It’s not “automated” the way a scraper normally would be, but it still works.
But there are other forums that do allow their sites to be scraped, like StackOverflow.
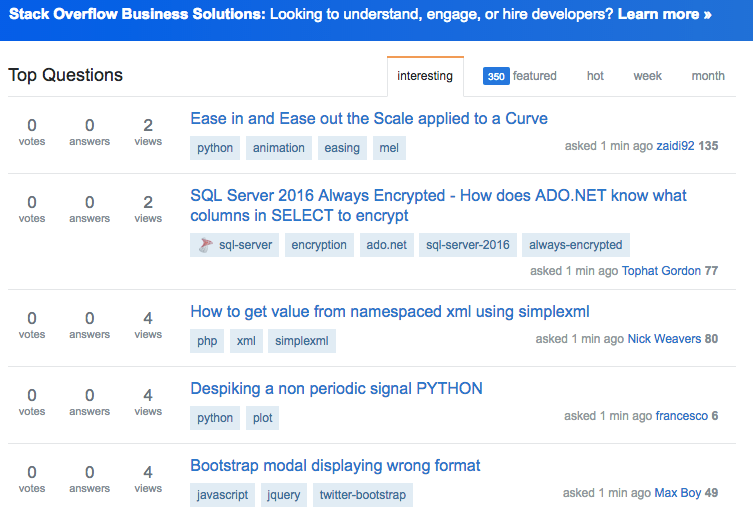
If you’re talking to other developers, or want to create content for SaaS owners, for example, then scraping the top questions from this site will come in handy.
And you can always use this scraped data for more than just backlinks, of course.
Using forums is a great way to come up with blog topics.
If you are using a scraping tool to pull top questions for blog inspiration, make sure your scraper is configured to pull posts that have answers.
This will save you quite a bit of time when you actually write your content later on.
7. Get more data for your blog posts
You can also scrape content that will help inform your blog posts.
Finding accurate data, whether it be a case study, report, or product information, can make the difference if you’re trying to write a high-quality post.
Let’s say you were going to do a product review on the top products from Amazon in specific categories (Home, Electronics, etc.).
You want to make sure that you have the right pricing information and the right features listed.
But Amazon is a big place. They don’t say “Earth’s biggest selection” for no reason.
The easiest thing to do is to use a web scraper that can pull product information automatically from sites like Amazon, eBay, or Google Shopping.
Tools like Webhose.io provide real-time data for thousands of sites, and they have a free plan for making up to 1,000 requests per month.

This can be helpful for marketers that want quick data from a large number of websites without spending hundreds of dollars on a larger web-scraping tool.
If you wanted to create a list of “The Best Email Marketing Software of 2018,“ for example, you could pull pricing and feature information from multiple sites at once to compile your list.
You can also pull data from sites like Statista to compile research for infographics or other shareable content.
Basically, you can find any data you need to make your blog posts better and more original.
This will not only help you create external links, but it will also improve the quality of your content.
And we all know that Google (and your audience) loves great content.
Tips for using content scrapers
When talking about web scrapers, it’s important to make sure that you’re using them for research and to inform your marketing practices.
Whatever you do, please don’t use them to plagiarize other people’s content.
Not only is it a big “no-no” for Google, but it’s also bad for building relationships with other blogs.
If you’re trying to build backlinks by becoming a guest poster, for example, you don’t want to steal that site’s content.
They’ll probably notice.
You also want to use tools that are considered “white hat” tools.
Black-hat scrapers — scrapers designed to steal content, for example — can be used for white-hat scraping, but you have to be vigilant about using them properly.
Scrapebox, the tool we mentioned earlier, can be used for both white and black-hat web scraping, for instance.

But most tools like this are designed for white-hat marketers, even if people use them for the wrong reasons.
If you truly want to automate the process, consider using tools that are “out-of-the-box” ready, meaning that you can plug in keywords or domain names, hit a button, and get results.
Web scraping can be incredibly complicated, especially if you don’t have a coding background.
Even if you do understand coding, there are plenty of things that can go wrong with a web scraper.
And many sites have proxies and other tools that can break web scrapers if they’re not well-designed.
For the most part, a web scraper like SEMRush should be enough to do the job.
But know that there are other options available to you if you want more data.
Conclusion
Web scraping can be a great thing for marketing research when done right.
First, be sure you use the right tool for the job. If you have a lot of heavy scraping to do, or you want to pull from multiple sites, consider using something more robust.
If you just want to pull blog titles and metadata, there are some plugins that will work well.
Just remember that all of it should be white hat, meaning that you’re not using that data to do malicious things.
Use it to find the most important information first: keywords, metadata, PPC ads, and inspiration for your blog.
And don’t forget to scrape your own site for that information, too.
The more you know about your own data, the better your marketing strategies will be.
How do you use scraping tools for white-hat strategy?
Unlock Thousands of Keywords with Ubersuggest
Ready to Outrank Your Competitors?
- Find long-tail keywords with High ROI
- Find 1000s of keywords instantly
- Turn searches into visits and conversions
Free keyword research tool









