

There’s no golden standard when it comes to organizing content on your website, whether that’s product listing pages, product detail pages, blog posts, or even images. However, one solution that most content management systems (CMS) offer are SEO category pages and tags.
Broad category pages (e.g. men’s shirts, women’s shoes) and more specific tag pages (e.g. white shirt, black jeans, etc.) can help you create an effective organization system. However, while they’re useful, too many category and tag pages may cause problems.
More specifically, they may impact search engine optimization (SEO) performance.
In this post, I’ll outline the potential problems of unnecessary or excessive category and tag pages. I’ll also introduce a solution for this problem—noindexing—and share an NP Digital client example that highlights the benefits of a well-placed noindex tag.
If you’re wondering if the noindex tag can solve your SEO problems, then read on.
What Problems Do Unnecessary Category and Tag Pages Cause?
Most concerns around category and tag style pages and their impact on SEO performance fall into one of two categories:
- Ranking conflicts
- Crawl depth/index bloat issues
In regards to the first category, ranking conflicts, unnecessary category and tag pages can be cannibalizing relevant content on your website. This means your internal pages are competing for the same traffic.
As for the second category, crawl/index bloat issues, you first need to understand what a search engine crawl bot is and how it works.
A search engine crawl bot, sometimes referred to as a crawler or a web spider, is a program that crawls the world wide web in order to maintain a list of active URLs. Once crawled, these pages are then indexed on search engines. This means they may show in search results.
The number of active pages on the internet is constantly fluctuating. So how do crawl bots know what pages to crawl?
Crawl bots use the website’s robot.txt file which contains a sitemap, or listing of website URLs:
Once it begins to crawl, it may also find other URLs via internal links on the crawled pages. It will crawl those pages, as well.
However, crawl bots cannot possibly crawl every single page on a website. As such, they crawl the pages which appear to be the most important ones.
That can be a problem for websites with many irrelevant pages, including category and tag pages. They can cause “crawl bloat,” which means the crawl bot is crawling unnecessary pages. This negatively impacts the website’s crawl budget which ultimately means that actually relevant pages are being missed.
How NP Digital Helped Our Client with Excess Category and Tag Pages
I founded NP Digital, my digital marketing agency, in 2017. I had one goal in mind: to help companies optimize, grow, and transform. My team has worked with hundreds of clients throughout that time.
In this instance, Client A was receiving traffic to one of their /tag/ pages. Although this is not necessarily a bad thing, it was for this client. Why? The /tag/ page had a very similar URL to the login page for their software. This was causing a lot of confusion for website users, and it resulted in a form of internal cannibalization.
How did NP Digital help?
By leveraging Google Search Console, my team was able to analyze how removing unnecessary category and tag pages led to an increase in traffic to the actual pages we wanted users to go to.
Let’s take a look.
What Results Did NP Digital Get by Noindexing Pages?
For the sake of simplicity, I will refer to the primary URL as the login page and the tag URL as the tag page.
The first step in my team’s analysis was to compare the login page and the tag page.
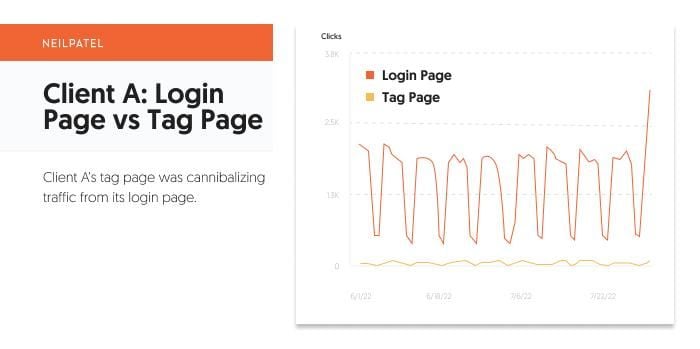
Here, it’s clear there is a splitting of the traffic between the login page and the tag page. While the tag page may be receiving significantly less traffic than the login page, it was still causing confusion and driving users away from the target URL.
As you might expect, this was due to the two pages competing for the same queries:

With this clear case of cannibalization, the team at NP Digital recommended noindexing URLs that did not serve the client. This includes the tag page which was being confused for the login page.
After this change, Google Search Console indicated there was an immediate drop in clicks to the tag page and an increase in clicks to the actual login page:
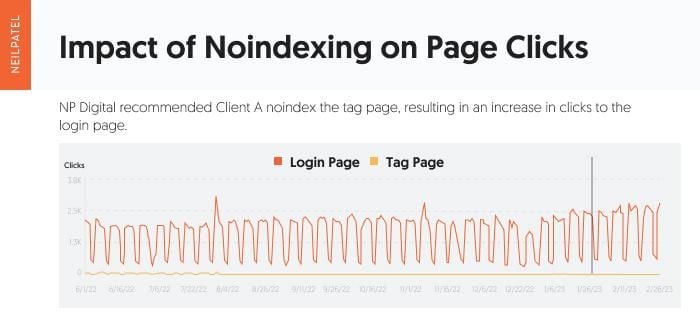
Now let’s take a look at the direct impact this noindexing had on both of the pages individually.
First up is the login page.
Using Google Search Console, my team analyzed the clicks and impressions from two time ranges. The primary time range was May 1, 2023, through May 31, 2023 (solid lines) with a year-over-year comparison to May 1, 2022 through May 31, 2022 (dotted lines). This ensures we are seeing data from after the noindexing (2023) and before the noindexing (2022).
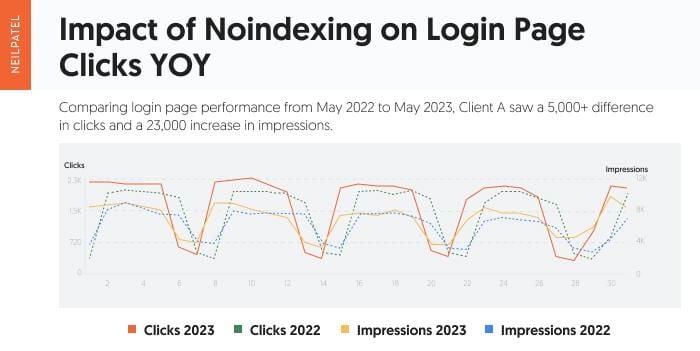
Note that there is a 5,000+ click difference year-over-year and a 23.5 thousand increase in impressions year-over-year.
To give some context to the above graph, my team also analyzed the search queries that were generating clicks and impressions for the login page:

It is important to note “[brand] login” along with derivations saw click and impression increases year-over-year as did the overall page.
Now let’s take a look at the tag page.
Just like for the login page, my team analyzed the clicks and impressions for the tag page. The primary time range was May 1, 2023, through May 31, 2023 (solid lines) with a year-over-year comparison to May 1, 2022 through May 31, 2022 (dotted lines).
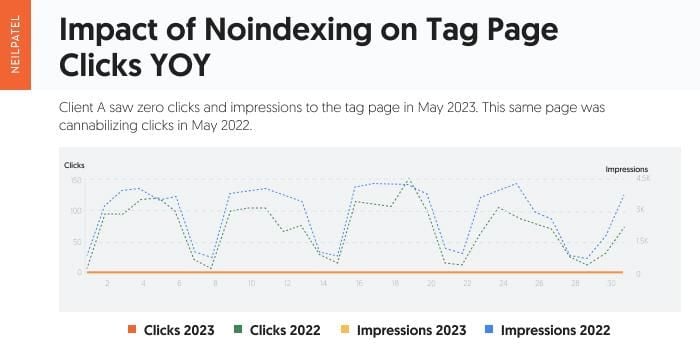
In the above image, the tag page saw zero clicks and zero impressions in May of 2023 due to the noindexing of the content. This is also clearly seen in the loss of search query clicks after the noindexing:
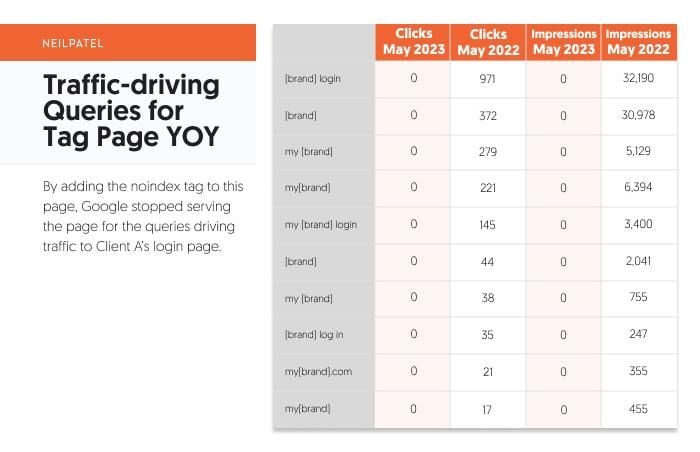
By adding a noindex tag to this page, Google no longer served this cannibalizing piece of content that was ranking for the same queries as the core login page. This helped to avoid confusion with our users, as well as Google.
Furthermore, this reduced crawl bloat and cleaned up the number of URLs we actually wanted indexed versus those that did not have value or even had negative impacts such as the one above.
This strategy is not recommended in ALL scenarios, but this is a specific scenario where it was beneficial to the client. This is a common case where “it depends” in SEO is actually accurate.
When Should You Index or Noindex Pages?
As stated above, noindexing pages is very much an “it depends” SEO tactic.
So how do you know when to index or noindex pages on your website?
Indexed pages should provide value to the user. They are pages that you want search engines to list so that users can find them.
The biggest reason to noindex a page on your website is when there is risk of cannibalization. This means the page’s content—or the URL—is so similar to a priority page on your website that it takes visits away from the priority page.
You may also noindex a page that you don’t need to advertise to the public. For example, a targeted landing page that you link to from an email newsletter, or a login portal for customers with an active account. You should also noindex staging environments and password protected pages.
Frequently Asked Questions
Website tags are keywords or terms applied to content to categorize it. For example, a blog post about digital marketing may include a marketing tag. Tagging on a website, then, is an attempt to group similar content together to make it easier to find.
Categories are broad topics that are meant to organize content on a website. For example, if you have a recipe blog, you may have categories like “breakfast,” “lunch,” “dinner,” etc. Tags are more specific labels, and each piece of content can have multiple tags associated with it. To continue the recipe blog example, that would be like tagging a chicken alfredo recipe with each of the main ingredients like “chicken,” “pasta,” “cream,” etc.
A noindex tag is a tag added to a webpage that tells crawl bots not to index the URL. As such, the page does not appear in search engine results. A nofollow tag is a tag added to a webpage that tells crawl bots not to crawl the URLs linked from that page. A webpage can be tagged as noindex, nofollow, or even both at the same time.
Conclusion
When it comes to organizing content on your website, categories and tags can be your best friends. You do need to be mindful of having too many category and tag pages indexed, though.
That’s where the noindex tag comes into play.
By noindexing superfluous category and tag pages, you remove the risk for content cannibalization and reduce crawl bloat issues. This is a win for your website’s performance and a win for site users who may be otherwise confused by redundant content.
Do you have questions about the pros and cons of noindexing pages on your website? Drop them in the comments below.