



Você já se preocupou com conteúdo duplicado?
Pode ser qualquer coisa: algum texto clichê no seu site. Ou, uma descrição de produto que você “pegou emprestado” do vendedor original. Ou, talvez uma citação que você copiou do seu blogger favorito ou uma autoridade no seu nicho.
Não importa o quanto você tente oferecer um conteúdo 100% único: você não pode.
O conteúdo duplicado está dentro dos 5 maiores problemas de SEO que os sites enfrentam.

É verdade: você NÃO CONSEGUE remover todos os trechos de conteúdo duplicado no seu site.
Matt Cutts do Google afirmou que o conteúdo duplicado acontece o tempo todo. Ele afirmou,
E o Google sabe disso.
Por tanto, não existe algo como uma PENALIDADE DO GOOGLE PARA CONTEÚDO DUPLICADO.
Sim, você leu certo.
O Google não penaliza sites que por conta disso. Que o Google vai atrás de sites que tenham X% de conteúdo duplicado é outro mito de SEO.
Agora, você provavelmente está se perguntando: se o Google não penaliza os sites que têm conteúdo duplicado, sobre o que é toda essa agitação?
Embora o Google não penalize sites por conta deste problema, ele o desencoraja. Vamos ver porque o Google desencoraja essa prática e em seguida olharemos para as diferentes maneiras para resolver os problemas de conteúdo duplicado no seu site.

Veja como minha agência pode aumentar drasticamente o tráfego do seu site
- SEO - Desbloqueie um volume enorme de tráfego através do SEO. Veja resultados reais.
- Marketing de Conteúdo - Nosso time cria conteúdo épico que vai ser compartilhado, linkado, e vai atrair tráfego.
- Mídia Paga - Estratégias de anúncios efetivas e com ROI claro.
Antes de começarmos, vamos ver como o Google define o que é isso.
O que é conteúdo duplicado
Aqui está a definição do Google:
O conteúdo duplicado geralmente se refere a blocos substanciais de conteúdo dentro ou através de domínios que correspondem totalmente a outro conteúdo ou são consideravelmente semelhantes.
Como pode ver pela definição do Google, o Google identifica dois tipos de conteúdo duplicado: o primeiro tipo é o que acontece no mesmo domínio e o outro tipo é o que acontece em vários domínios.
Aqui estão alguns exemplos para entender os diferentes tipos.
Trechos de conteúdo duplicado no mesmo domínio
Como pode ver, esse é o tipo de duplicação que acontece dentro do seu site.
Pense nesse conteúdo como o mesmo que aparece em diferentes lugares do seu site.
Pode ser que:
- Este conteúdo está presente em seu site em diferentes locais (URLs).
- Ou, talvez pode ser alcançado através de diferentes maneiras (por isso resultam em URLs diferentes). Por exemplo, essas poderiam ser as mesmas postagens que são mostradas quando uma pesquisa é feita com base nas diferentes categorias e tags no seu site.
Vamos ver alguns exemplos de diferentes tipos de conteúdo duplicado no mesmo site.
Conteúdo clichê:
Simplificando, o conteúdo clichê está disponível em diferentes seções ou páginas em seu site.
A Ann Smarty classifica o conteúdo clichê como:
- (Site inteiro) Navegação global (home, sobre, etc)
- Determinadas áreas especiais, especialmente se incluem links (lista de blogs, barra de navegação)
- Marcadores (javascript, nomes de id/classe CC como header, footer)
Se você olhar para um site padrão, ele normalmente terá um cabeçalho, um rodapé e uma barra lateral. Além destes elementos, a maioria dos CMS permitem mostrar as mensagens mais recentes ou suas postagens mais populares na página inicial também.
Quando os robôs de busca rastreiam seu site, eles vão ver que esse conteúdo está presente várias vezes nele, e de fato, é um conteúdo duplicado.
Mas esse tipo de conteúdo duplicado não prejudica seu SEO. Os robôs dos mecanismos de busca são sofisticados o suficiente para entender que a intenção por trás deste conteúdo não é malicioso. Então, você está seguro.
Estruturas inconsistentes de URL:
Veja as seguintes URLs –
www.seusite.com/
seusite.com
https://seusite.com
https://seusite.com/
Eles parecem o mesmo para você?
Sim, você está certo, a URL de destino é a mesma. Então, pra você, elas significam a mesma coisa. Infelizmente, os robôs de mecanismos de busca as leem como URLs diferentes.
Mas, quando os robôs de mecanismos de busca se deparam com o mesmo conteúdo em duas URLs diferentes: https://seusite.com e https://seusite.com, eles consideram como conteúdo duplicado.
Esse problema se aplica para URLs geradas para o fim de rastreamento como:
https://seusite.com/?utm_source=newsletter4&utm_medium=email&utm_campaign=holidays
As URLs com parâmetros de rastreamento também podem causar este tipo de problema.
Domínios localizados:
Suponha que você atende a diferentes países e criou domínios localizadas para cada país que atende.
Por exemplo, você pode ter uma versão .de do seu site para a Alemanha e uma versão .au para a Austrália.
É natural que o conteúdo vá coincidir em ambos os sites. A menos que você traduza o seu conteúdo para o domínio .de, os mecanismos de busca irão achar que o seu conteúdo seja duplicado em ambos os sites.
Nesses casos, quando um pesquisador procurar pelo seu negócio, o Google irá mostrar qualquer uma dessas duas URLs.
O Google muitas vezes vê o estado do pesquisador. Suponha que o pesquisador esteve presente na Alemanha. Google vai, por padrão, mostrar apenas seu domínio .de. No entanto, o Google pode não acertar.
Trechos de conteúdo duplicado em diferentes domínios
Conteúdo copiado:
Copiar o conteúdo de um site (sem permissão) é errado e o Google também acha isso. Se você só oferecer isso, seu site estará em risco. O Google pode não mostrá-lo nos resultados de busca ou deixá-lo longe das primeiras páginas de resultados.
Curadoria de Conteúdo:
A curadoria de conteúdo é o processo de procurar por histórias que são relevantes para seus leitores. Essas histórias podem ser de qualquer lugar da internet.
Visto que uma postagem de curadoria de conteúdo faz uma lista de pedaços de conteúdo vindo de todos os lugares da internet, é natural que a postagem contenha conteúdo duplicado (mesmo se for somente os títulos). A maioria dos blogs pedem trechos e citações também.
Novamente, o Google não vê isso como um SPAM.
Desde que você forneça alguma ideia, uma nova perspectiva ou explique as coisas da sua própria maneira, o Google não vai ver essa duplicação como conteúdo malicioso.
Compartilhamento de conteúdo:
O compartilhamento de conteúdo é cada vez mais um tática comum de marketing de conteúdo. A Curata descobriu que o mix ideal de marketing de conteúdo tinha cerca de 10% de contribuição de conteúdo compartilhado.
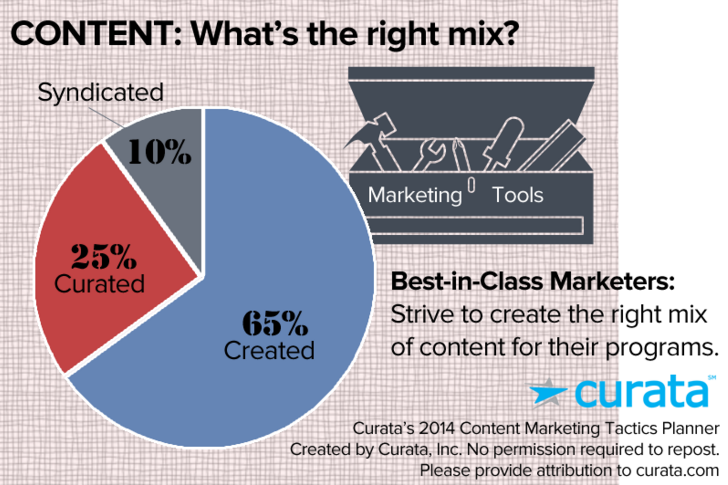
Como a Search Engine Land diz, “Compartilhamento de conteúdo é o processo de levar o seu blog, site ou conteúdo em vídeo para sites de terceiros, como um artigo, trecho, link completo ou uma miniatura.”
Sites que distribuem conteúdo oferecem seu conteúdo para ser publicado em vários sites. Isso significa que várias cópias existem de qualquer post compartilhado.
Se você conhece bem o Huffington Post, você sabe que ele permite distribuição de conteúdo. Todos os dias ele apresenta histórias de toda a web e republica elas com a devida permissão.
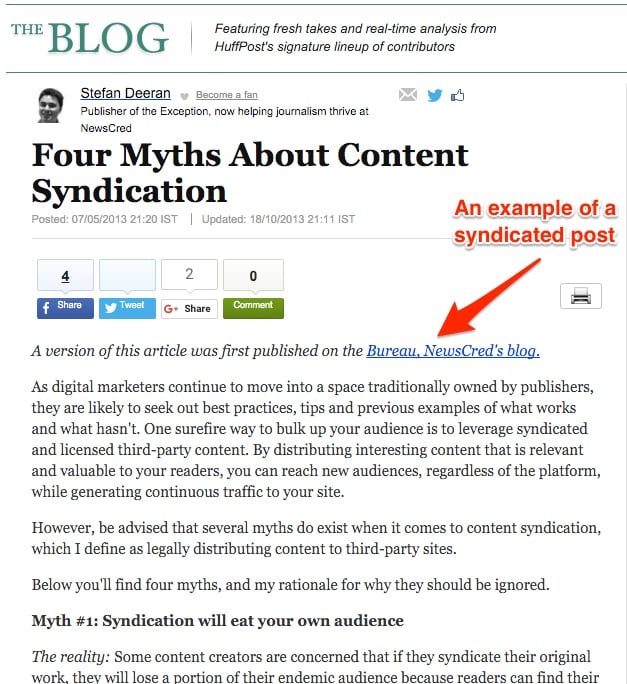
O Buffer também compartilha conteúdo. Seu conteúdo é republicado em sites como o Huffington Post, Fast Company, Inc. e muitos outros.
A imagem seguinte mostra o tráfego que tal conteúdo compartilhado traz para o seu site.
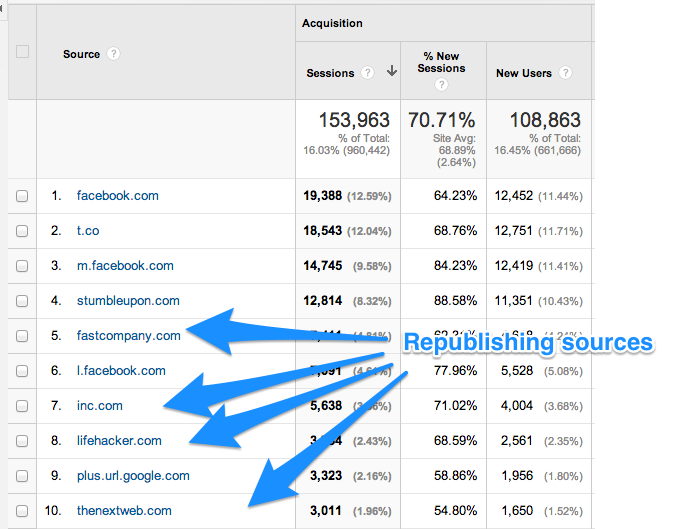
Embora esses casos sejam taxados como duplicação de conteúdo, o Google não irá penalizá-los.
A melhor maneira de compartilhar conteúdo é pedir para que sites republiquem e declarem você como o criador do conteúdo original e também que eles façam links de volta para o seu site, ou seja, para o post do conteúdo original.
Roubo de conteúdo:
Roubo de conteúdo é sempre algo complicado de se tratar quando você está discutindo sobre esses tipos de problema.
O Wikipedia define o roubo na web (ou o roubo de conteúdo) como:
Roubo da web (coletar ou extrair dados da web) é uma técnica de programas de computador que extrai informações de sites.
Curiosamente, até mesmo o Google rouba dados para oferecer-los imediatamente na primeira SERP.
Então, não é de admirar que o Matt Cutt tuitou,
Se você vir uma URL que roubou e que passou a fonte do conteúdo original no ranking no Google, por favor nos avise…
criou um pouco de estardalhaço.
Dan Barker respondeu com este tweet:
@mattcutts Eu acho que encontrei um, Matt. Perceba as semelhanças nos textos dos conteúdos:
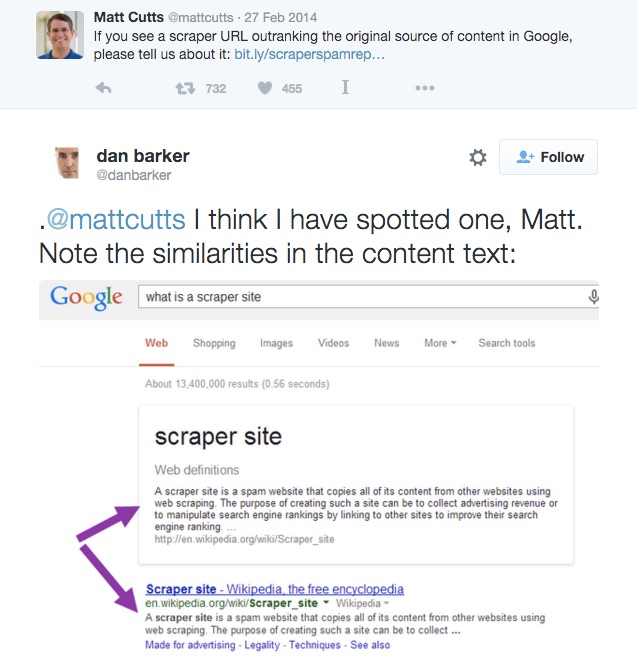
Como pode ver, o Google pega o conteúdo do primeiro resultado e mostra diretamente no SERP. Isto é, sem dúvida, roubo de conteúdo.
Então, descartar o roubo como um conteúdo negligenciado não será certo em todos os casos.
No entanto, se você pesquisar um pouco mais, você verá que o Google não tolera sites que roubam conteúdos.
Agora que você tem uma ideia razoável sobre o que conta como conteúdo duplicado, vamos ver as ocorrências que não são casos disso, mas mesmo assim os webmasters se preocupam demais sobre elas.
O que não é contado como conteúdo duplicado
Conteúdo traduzido:
O conteúdo traduzido NÃO É um conteúdo duplicado. Se você tem um site e você quer importar seu conteúdo para diferentes países e traduzir seu conteúdo principal para os idiomas locais, você não irá enfrentar nenhum problema de duplicação de conteúdo.
Mas este exemplo não é tão direto. Se você usar algum programa ou até mesmo o Google Tradutor, a qualidade da tradução não será perfeita.
E, quando a tradução não faz sentido de forma natural e falta uma análise pessoal, o Google pode ver este conteúdo como um spam, ou conteúdo duplicado.
Tal conteúdo pode ser facilmente identificado como algo gerado por programas e pode deixar o Google em alerta.
A melhor maneira de evitar esse problema é contratar um tradutor para fazer o serviço. Ou, faça um trabalho decente com um bom programa e então peça para um tradutor profissional revisar o conteúdo.
Por revisar o conteúdo traduzido, você irá garantir que a qualidade do conteúdo seja alta e o Google, portanto, não irá achar que é um conteúdo duplicado.
Mas, se por algum motivo você não poder fazer nenhuma das duas sugestões acima, então você deve bloquear o conteúdo traduzido por programas de ser revisado por robôs usando o robots.txt (eu irei lhe mostrar como fazer isso nas seções seguintes).
Conteúdo de site mobile:
Se você não tem um site responsivo, pode ser que você tenha desenvolvido uma versão mobile separada do seu site principal.
Então, você vai ter URLs diferentes que entregam o mesmo conteúdo, como:
http: seusite.com – Versão web
http.m.seusite.com – Versão mobile
Tendo o mesmo conteúdo nas versões do seu site web e mobile não conta como conteúdo duplicado. Além disso, você deve saber que o Google tem diferentes robôs de busca que rastreiam sites mobile, assim você não precisa se preocupar com este caso.
O Google pode identificar trechos de duplicação que são feitos com uma intenção maliciosa. Você nunca está em risco se não está tentando burlar o sistema. Mas, você ainda deve evitar situações com esse tipo de conteúdo por eles darem impacto no seu SEO.
Veja como esse problema pode fazer o seu SEO sofrer:
Problemas causados por conteúdo duplicado
Problema #1 – Diluição da popularidade do link
Quando você não define uma estrutura de URL consistente para o seu site, você acaba criando e distribuindo versões diferentes dos links do seu site quando começar a construir links.
Para entender isso melhor, imagine que você criou um recurso épico que produziu uma tonelada de inbound links (outros sites fazendo links para o seu conteúdo).
No entanto, você não vê a autoridade da página desse recurso aumentando tanto quanto o esperado.
Por que a autoridade da página não decolou, apesar de todos os links e engajamento?
Talvez isso não aconteceu porque diferentes sites estão fazendo o backlink de volta para o recurso utilizando diferentes versões da URL do seu recurso.
Como:
https://www.seusite.com/recurso
https://seusitesite.com/recurso
E assim por diante…
Você viu como o conteúdo duplicado arruinou suas chances de criar uma página com uma autoridade superior?
Tudo porque os mecanismos de busca não podem interpretar que todas as URLs estão apontando para o mesmo local de destino.
Problema #2 – Apresentando URLs não amigáveis
Quando o Google vem através de dois recursos idênticos ou um pouco semelhantes na web, ele escolhe por mostrar um deles para o pesquisador. Na maioria dos casos, o Google irá selecionar a versão mais apropriada do seu conteúdo. Mas, ele não vai acertar o tempo todo.
Pode acontecer que, para uma determinada consulta de pesquisa, o Google acabe mostrando uma versão da URL do seu site não muito boa.
Por exemplo, se um pesquisador estava procurando por seu negócio online, qual das seguintes opções você gostaria de mostrar a seu visitante:
https://seusite.com
ou https://seusite.com/sobre.html
Eu acho que você estaria interessado em mostrar a primeira opção.
Mas, o Google pode mostrar apenas a segunda.
Se você evitasse o exemplo que foi dito, em primeiro lugar, não teria acontecido essa confusão e o usuário só veria a melhor e mais popular versão da sua URL.
Problema #3 – Apagando os recursos dos rastreadores dos mecanismos de busca
Se você entende como rastreadores trabalham, você sabe que o Google envia seus robôs de busca para indexar o seu site, dependendo da sua frequência de publicação de conteúdos novos.
Agora, imagine que os rastreadores do Google visitem o seu site e eles rastreiam cinco URLs apenas para descobrir que todos eles oferecem o mesmo conteúdo.
Quando os robôs de busca descobrem e indexam o mesmo conteúdo em diferentes lugares do seu site, você perde ciclos de rastreamento.
Esses ciclos de rastreamento poderiam ter sido usados para rastrear e indexar qualquer conteúdo recentemente publicado que você acabou de adicionar em seu site. Isso não vai apenas desperdiçar os recursos de rastreamento como irá afetar o seu SEO.
Como o Google lida com conteúdo duplicado
Quando o Google encontra trechos de conteúdo idênticos, ele decide mostrar um deles. A escolha do recurso a mostrar nos resultados de busca vai depender dos termos de busca.
Se você possui o mesmo conteúdo no seu site e oferece uma versão para impressão também, o Google levará em consideração se a pessoa que está fazendo a busca está interessada na versão para impressão. Se sim, apenas a versão para impressão do conteúdo será alcançada e apresentada.
Você talvez notou mensagens num SERP indicando que outros resultados similares não foram mostrados. Isso acontece quando o Google decide mostrar uma das dezenas de cópias de conteúdos parecidos.
Este tipo de conteúdo nem sempre é tratado como um SPAM. Ele se torna um problema apenas quando tem o objetivo de abusar, enganar e manipular os rankings nos mecanismos de busca.
O Google leva conteúdos duplicados a sério e pode até mesmo banir seu site se você tentar enganar o mecanismo de busca usando isso.
A política de conteúdo duplicado do Google diz:
Nos raros casos nos quais o Google percebe que aquele conteúdo duplicado pode estar sendo mostrado com a intenção de manipular nossos rankings e enganar nossos usuários, nós também faremos os ajustes apropriados na indexação e no ranqueamento dos sites envolvidos. Como resultado, o ranking do site pode sofrer ou o site pode ser completamente removido da indexação do Google, o que levará com que o site não apareça mais nos resultados de busca.
Como você viu acima, a maioria dos casos desse tipo de conteúdo acontece sem intenção. Mesmo que você possa estar usando textos clichês no seu site. Além disso, pode ser que diferentes sites estão copiando e republicando seu conteúdo sem sua permissão.
Existem diferentes maneiras que você pode usar para verificar se seu site possui algum problema deste tipo. Vamos ver algumas opções.
Como identificar problemas de conteúdo duplicado
Método #1: Faça uma simples busca no Google
A forma mais fácil de detectar problemas disso em seu site é fazer uma simples busca no Google.
Apenas busque por uma palavra-chave que você tem no ranking e observe os resultados do mecanismo de busca. Se você descobrir que o Google está mostrando uma URL não-amigável ao usuário do seu conteúdo, então você tem conteúdo duplicado no seu site.
Método #2: Procure por avisos no Google Webmasters
O Google Search Console também alerta proativamente sobre exemplos de conteúdo duplicado em seu site.
Para encontrar alertas do Google sobre isto, faça o login na sua conta do Google Webmasters. Se você já estiver logado, pode simplesmente clicar neste link.
Método #3: Confira as métricas dos Rastreadores no seu painel do Webmasters
As métricas dos rastreadores mostram o número de páginas que os rastreadores do Google rastrearam em seu site.
Se você vir rastreadores rastreando e indexando centenas de páginas em seu site enquanto você só tem algumas, você está provavelmente usando URLs inconsistentes. E, portanto, os rastreadores do mecanismo de busca está rastreando o mesmo conteúdo várias vezes em diferentes URLs.
Para ver as métricas dos Rastreadores, entre em sua conta do Google Webmasters, clique na opção de Rastreamento no lado esquerdo do painel. Quando o menu se expandir para baixo, clique na opção Estatísticas de Rastreamento.
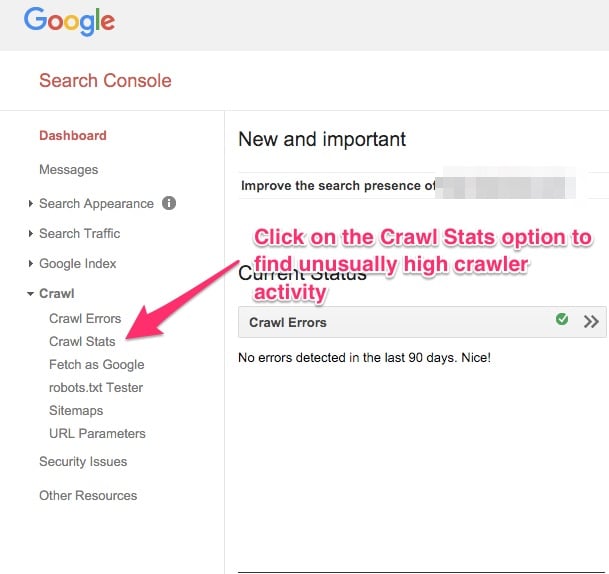
Se você vir alguma atividade alta de rastreamento de busca e isso for incomum, você deveria verificar a estrutura da URL e ver se seu site está usando URLs inconsistentes.
Método #4: Screaming Frog
O Screaming Frog é uma ferramenta de revisão do SEO para desktop que rastreia o seu site como os indexadores de busca. Você pode pegar vários tipos de problemas de conteúdo duplicado com ele.
Passos para usar o Screaming Frog para achar esses problemas:
1. Visite o site oficial do Screaming Frog e baixe uma cópia compatível com seu sistema.
Por favor, note que a versão gratuita do Screaming Frog só pode ser usada para rastrear até 500 páginas. Isso é o suficiente para a maioria dos sites.
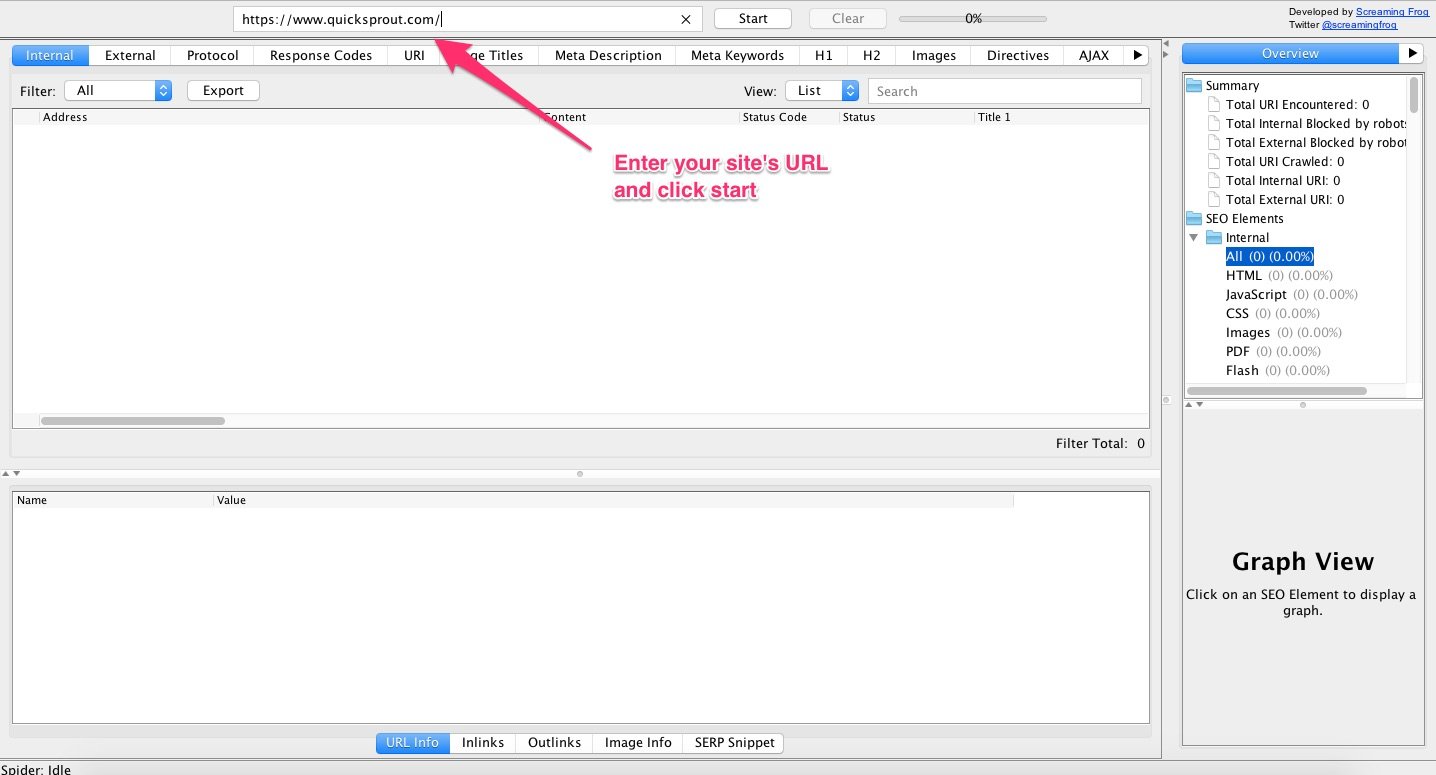
2. Quando você tiver instalado o programa, entre nele e coloque sua URL. Clique em start (iniciar).
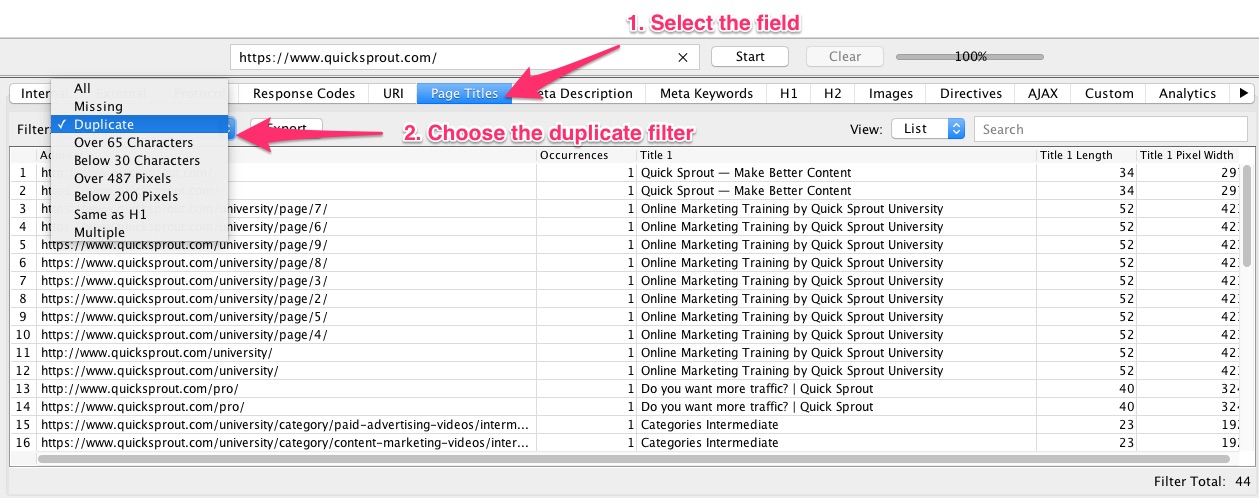
3. Quando o Screaming Frog rastreia o seu site, você pode clicar no campo que deseja verificar o conteúdo duplicado, como URLs, títulos da página, meta descrições e assim por diante.
Depois de selecionar o campo, escolha o filtro duplicate. Usando este método, você pode detectar todas as ocorrências disso em seu site.
Método #5: Buscar por blocos de conteúdo
Este método é um pouco bruto, mas caso suspeite que seu conteúdo está sendo copiado em locais diferentes ou está presente em diferentes lugares em seu site, você também pode tentar isso.
Copie um bloco de texto aleatório do seu conteúdo e faça uma simples busca no Google. Lembre-se de não usar parágrafos longos, uma vez que irá retornar um erro.
Pegue 2-3 sentenças de um parágrafo e procure por elas no Google.
Se os resultados da pesquisa mostrarem diferentes locais que o seu conteúdo está postado, você provavelmente é uma vítima de plágio.
Usando os métodos acima, você pode facilmente identificar estes problemas em seu site. Agora, vamos dar uma olhada em algumas soluções para lidar com isto.
4 soluções para tratar o problema de conteúdo duplicado
1. Consistência
Como você viu na seção anterior, a maioria destes casos acontecem quando a estrutura de URL é inconsistente.
Sua melhor solução aqui é padronizar a estrutura de links que você prefere. Poderia ser o www ou a versão não-www. Ou talvez o HTTP ou a versão HTTPS – seja o que for, ele precisa ser consistente.
Você pode informar o Google sobre a sua versão preferida de URL, definindo ela na sua conta do Google Webmasters.
Após logar, clique em ferramentas (engrenagem) no topo direito. Então, selecione Configurações do Site.
Aqui você pode ver a opção de definição do seu domínio preferido:
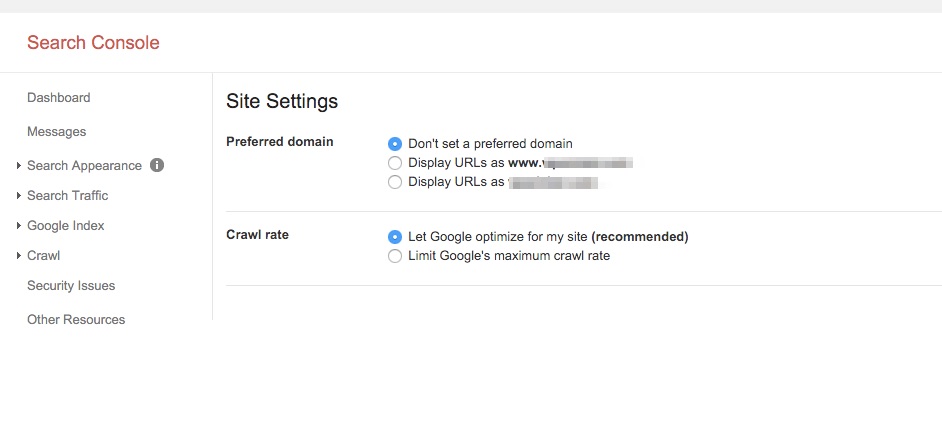
Benefícios de definir o domínio de sua preferência:
- Ordena as questões de conteúdo duplicado com a versão www e a versão não-www
Você agora já sabe que os robôs do Google irão tratar seusite.com e www.seusite.com como duas páginas diferentes e contam o mesmo conteúdo neles como conteúdo duplicado.
Simplesmente definindo seu domínio preferido, você pode pedir ao Google para apenas rastrear e indexar um deles e você também remove todos os riscos da duplicação de conteúdo acontecer.
- Mantenha o link juice (transmissão de PageRank)
A definição de um domínio preferido ajuda seu site reter a transmissão de PageRank, mesmo quando um site está fazendo um backlink para uma versão não preferida do seu site.
Um trecho do recurso do Google:
Por exemplo, se você especificar o domínio de sua preferência como https://www.exemplo.com e nós encontrarmos um link para seu site, que é formatado como https://exemplo.com, seguimos o https://www.exemplo.com em vez do anterior.
Além disso, vamos levar a sua preferência em consideração ao exibir as URLs. Se você não especificar um domínio de sua preferência, podemos tratar as versões www e não-www do domínio como referências separadas para páginas separadas.
A opção de domínio preferido do Google praticamente cuida das inconsistências da versão www e da não-www do seu site.
Depois de definir o seu domínio preferido nas configurações do Google Webmaster, o próximo passo deve ser a criação dos redirecionamentos 301 de todos os links de domínio não-preferenciais em seu site para os seus preferidos. Isso ajudará os mecanismos de busca e os visitantes a aprenderem sobre a sua versão preferida.
No entanto, pode haver outras inconsistências que mencionei acima. Para organizá-las, você não deve apenas escolher uma versão preferida da URL, mas também escolher a sintaxe exata que sua equipe deve utilizar quando forem fazer links a qualquer conteúdo em seu site.
Você também pode ter um guia modelo que pode ser distribuído internamente para mostrar a maneira padrão de compartilhamento de URLs. Basicamente, quando você compartilhar um link para qualquer página ou post em seu site, deve certificar-se de que o mesmo formato de link seja usado todas as vezes.
Lembre-se que os mecanismos de busca iriam tratá-los de forma diferente: https://www.seusite.com/pagina/ e https://www.seusite.com/pagina e https://www.seusite.com/pagina/index.htm. Portanto, escolha um formato e mantenha a consistência.
2. Canonicalização
A maioria dos CMSs permite que você organize seu conteúdo usando tags e categorias. Muitas vezes, quando os usuários buscam por uma tag ou pesquisam com base em uma categoria, os mesmos resultados aparecem. Dessa forma, os robôs dos mecanismos de busca podem pensar que ambas as URLs oferecem o mesmo conteúdo.
https://www.seusite.com/alguma-categoria
e
https://www.seusite.com/alguma-tag
Esse problema é mais grave em sites de e-commerce, onde um único produto pode ser alcançado usando vários filtros (resultando assim, em várias URLs possíveis).

É verdade que as categorias, tags, filtros e caixas de pesquisa ajudam você a organizar o seu conteúdo e tornam fácil para os seus visitantes encontrarem o que precisam.
Mas, como você pode ver na imagem acima, tais pesquisas resultam em várias URLs e assim causam problemas de conteúdo duplicado.
Quando as pessoas procuram pelo seu conteúdo no Google, estes múltiplos links podem confundir os robôs do Google e ele pode acabar mostrando uma versão não-amigável do seu recurso, como https://www.seusite.com/?q=termo de busca nos resultados da busca.
Para evitar esse problema, o Google recomenda que você adicione uma tag canonical para a URL preferida do seu conteúdo.
Quando um robô dos mecanismos de busca vai em uma página e vê a tag canonical, ele pega o link para o recurso original. Além disso, todos os links para qualquer página duplicada são contados como links para a página original. Assim, você não perde qualquer valor no SEO por conta desses links.
A canonicalização pode ser implementada de diversas maneiras:
Método 1: Definir a versão preferida: www e a não-www
Definir a versão preferida do seu domínio, como discutimos na seção anterior, é também uma forma de canonicalização.
Mas, como você deve saber, isso aborda o tema de uma maneira muito vasta. Isso não vai lidar com questões da duplicação de conteúdo que o CMS gera.
Método 2: Apontar manualmente o link canônico para todas as páginas
Neste método, você deve começar por definir o seu recurso original. O recurso original é a página que você deseja disponibilizar aos seus leitores cada vez que eles pesquisarem.
O recurso original é também a página que você deseja definir como sua página preferida para sinalizar aos robôs dos mecanismos de busca.
Use os métodos listados na seção acima para identificar os casos de conteúdo duplicado em seu site. Em seguida, identifique as páginas que oferecem conteúdo semelhante e escolha o recurso original para cada um.
Após as duas etapas acima, você está pronto para usar a tag canonical.
Para fazer isso, você terá que acessar o código fonte do recurso, e na sua tag <head>, adicione a seguinte linha:
<link rel=”canonical” href=”https://seusite.com/categoria/recurso” />
Aqui, “https://seusite.com/categoria/recurso” é a página que você deseja chamar o recurso original.
Você vai seguir o mesmo processo em cada página similar.
Meu blog em Crazy Egg suporta categorias. Assim, as mensagens são acessíveis através da lista do blog na homepage, bem como através das diferentes categorias.
Eu uso a tag rel=canonical para marcar a minha URL preferida para cada página e post.
Olhe para a imagem seguinte mostrando a tag:

Usar a tag canonical é uma maneira fácil de informar o Google sobre o link que você gostaria que o Google mostre aos usuários quando eles pesquisarem.
Como você provavelmente deve saber, o meu site é construído no WordPress e eu estou usando o plugin Yoast SEO. Esse plugin permite que você defina a sua versão preferida de cada página e post. Assim, você não precisa se preocupar com sua mensagem estar acessível ou aparecendo em URLs diferentes.
Se o seu site é construído no WordPress, eu recomendo que instale este plugin. Você pode encontrar a opção de URL canonical nas configurações avançadas do plugin.
Se um post ou página que você criou é a própria versão preferida, deixe a tag Canonical URL em branco. Se não for, adicione o link para a versão preferida do recurso no campo Canonical URL.
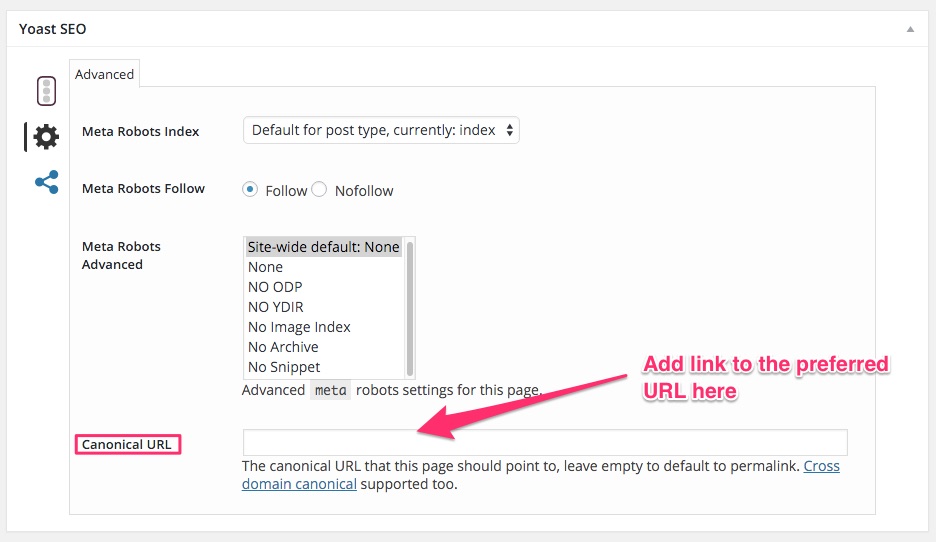
Método 3: Configurar os redirecionamentos 301
Muitas vezes, a reestruturação dos sites resultam em problemas de duplicação do conteúdo. Reestruturar um formato de link também pode criar várias cópias do mesmo conteúdo.
Para reduzir o impacto desses problemas, configure os redirecionamentos 301. Os redirecionamentos 301 de URLs não preferenciais de um recurso para suas URLs preferidas são uma ótima maneira de alertar os mecanismos de busca sobre a sua preferência.
Quando um robô dos mecanismos de busca vai para uma página e vê um redirecionamento 301, ele atinge o recurso original através da página de conteúdo duplicado. Nesses casos, todos os links para a página duplicada são tratados como links para a página original (nenhum valor do SEO é perdido).
Dependendo do seu site, você poderia usar estas diferentes maneiras de configurar os redirecionamentos 301. Se você tem dúvidas sobre a criação de redirecionamentos, a seu provedor de hospedagem deve ser capaz de ajudar.
Se você usa o WordPress, pode usar um plugin como o Redirection que cria redirecionamentos 301.
Seja qual for o método escolhido, eu sugiro realizar um teste para os links quebrados, configurando os redirecionamentos para darem errado.
3. Meta tag Noindex
As meta tags são uma maneira dos webmasters darem aos mecanismos de busca informações importantes sobre os seus sites.
A meta tag noindex diz para os robôs dos mecanismos de busca para não indexarem um determinado recurso.
As pessoas muitas vezes confundem a meta tag noindex com a meta tag nofollow. A diferença entre eles é que, quando você usa o tag noindex e a nofollow, você está pedindo os mecanismos de busca para não indexarem e não seguirem a página.
Considerando que, quando você usa as tags noindex e follow, você está solicitando os mecanismos de busca para não indexar a página, mas não ignorarem quaisquer links para/da página.
Você pode usar a meta tag noindex para evitar que os mecanismos de busca indexem suas páginas com esse tipo de conteúdo.
Para usar a meta tag com a finalidade de lidar com esses casos, você deve adicionar a seguinte linha de código dentro da tag head da sua página de conteúdo duplicado:
<Meta Name=”Robots” Content=”noindex,follow”>
Usar a tag follow junto com a tag noindex garante que os motores de busca não ignorem os links nas páginas duplicadas.
4. Use a tag hreflang para lidar com sites locais
Quando você usa conteúdo traduzido, você deve usar a tag hreflang para ajudar os motores de busca escolher a versão correta do seu conteúdo.
Se você tem o seu site em inglês e você traduziu para o espanhol para servir o público local, você deve adicionar a tag, “<link rel=”alternate” href=”https://exemplo.com” hreflang=”en-es” />” para a versão espanhola do seu site.
Você deve seguir o mesmo processo para todas as diferentes versões locais do seu site. Isto irá remover o risco de mecanismos de busca considerá-las como conteúdo duplicado e também irá melhorar a experiência do usuário quando os usuários quiserem interagir com o seu site em sua língua nativa.
5. Use a hashtag em vez do ponto de interrogação quando tiver usando os parâmetros UTM
É comum o uso de parâmetros de rastreamento como a fonte, campanha e meio para medir a eficácia de diferentes canais.
No entanto, como discutimos anteriormente, quando você cria um link como https://seusite.com/?utm_source=newsletter4&utm_medium=email&utm_campaign=feriados, os mecanismos de busca o rastreiam e o entendem como um caso de conteúdo duplicado.
Uma solução fácil é usar o operador # em vez do ponto de interrogação. Quando os robôs dos mecanismos de busca se depararem com o sinal # em uma URL, ignoram tudo o que segue depois do sinal, evitando assim problemas de duplicação de conteúdo.
6. Tenha cuidado com o compartilhamento de conteúdo
Se você permitir que diferentes sites republiquem o seu conteúdo, sempre peça a eles que façam links de volta para o seu site. Solicitar os sites que republicaram a usar a tag rel ou a tag noindex também pode ajudá-lo a evitar problemas de conteúdo duplicado causados devido à republicação.
Como não tratar conteúdo duplicado
Como eu tenho dito, isto acontece o tempo todo. Se você também encontrou em seu site qualquer exemplo disso, deve corrigi-los. Eu já mostrei diferentes maneiras de fazer isso.
No entanto, agora eu gostaria de mostrar algumas maneiras que não são corretas e não devem ser usadas para corrigir problemas de com isto.
1. Não bloqueie URLs com o robots.txt
Em primeiro lugar o que é robots.txt? Robots.txt é um arquivo de texto com as mensagens que você deseja comunicar aos rastreadores dos mecanismos de pesquisa. Estas mensagens podem ser para solicitar que os indexadores de busca não indexem URLs específicas.
Alguns webmasters especificam URLs que contenham conteúdo duplicado nos arquivos robot.txt, e, assim, tentam bloquear os mecanismos de busca do rastreamento.
O Google desencoraja práticas que bloqueiam rastreadores de alguma maneira. Quando as páginas são impedidas de serem rastreadas, os robôs do Google contam elas como páginas exclusivas, enquanto eles deveriam saber que elas não são páginas exclusivas, mas simplesmente páginas com conteúdo duplicado.
O segundo problema com esse tipo de bloqueio é que outros sites ainda podem ser capazes de se conectarem a uma página bloqueada. Se um site de alta qualidade faz um link para uma página bloqueada e os robôs dos mecanismos de busca não conseguem rastrear ou indexar essa página, você não vai ter o benefício SEO desse backlink.
Além disso, você pode sempre marcar páginas duplicadas como sendo duplicadas usando a tag “canonical”.
2. Não use spun article para torná-lo “único”
Spun Article é uma forma robotizada de alterar os seus artigos, colocando novas palavras-chave nele. Os robôs do Google podem dizer se o seu conteúdo é reformulado ou gerado por robôs. Então, reescrever um conteúdo ou apenas reformulá-lo para parecer que é único, não vai ajudar.
Publicar um conteúdo robotizado vai indicar aos mecanismos de busca que você está praticando táticas obscuras para manipular rankings de busca. Isso pode fazer com que o Google acabe tomando medidas contra o seu site.
3. Não use a opção “Remover URLs” do Google Webmasters
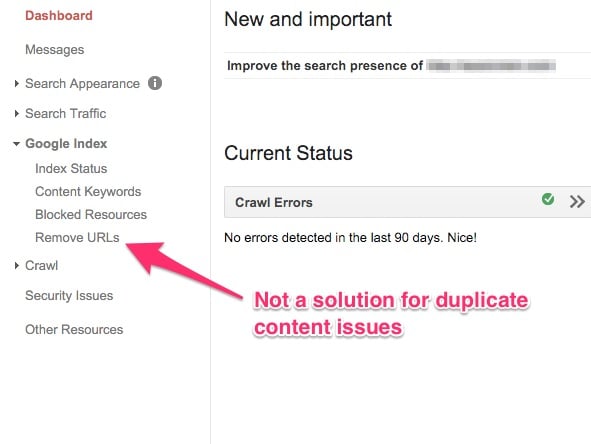
Se você notou, o Google Webmasters lhe dá a opção de remover URLs do seu site.
Assim, poucos webmasters escolhem uma versão não-amigável do seu recurso que aparece nos resultados de pesquisa e a removem ele usando a opção acima.
O problema com esta solução é que as URLs só são removidos temporariamente. E, o seu site ainda vai enfrentar todos os problemas que eu mencionei anteriormente. Esta, então, não é uma solução.
Esse recurso é útil quando você deseja remover algo do seu site e quer uma solução rápida até que você trabalhe nisso para resolvê-lo. Isso não ajuda com problemas que estamos mencionando no post.
Conclusão
A maioria dos problemas de conteúdo duplicado podem ser evitados ou corrigidos.
Será que você verificou o seu site para ver os problemas de conteúdo duplicado? Se estiver presente, quais os métodos você vai usar para resolvê-los?








