
¿Alguna vez te has preocupado por el contenido duplicado?
Podría ser cualquier cosa: algún texto calificativo en tu sitio web. O una descripción de un producto que hayas tomado del vendedor original. Quizás incluso una cita que copiaste de tu bloguero favorito o de una autoridad en el tema.
No importa lo mucho que trates de ofrecer un contenido 100% único, simplemente no puedes.
El contenido duplicado está entre los 5 principales problemas de SEO que los sitios web enfrentan.

Es cierto: NO PUEDES eliminar todas las instancias el contenido duplicado de tu sitio web.
Matt Cutts de Google ha declarado que el contenido duplicado sucede por toda la red, todo el tiempo. Cutts declaró,
Y Google lo entiende.
Por lo tanto, no existe la PENALIZACIÓN POR CONTENIDO DUPLICADO DE GOOGLE.
Sí, leíste bien.
Google no penaliza a los sitios web que usan contenido duplicado. El hecho de que Google vaya detrás de aquellos sitios web que cuentan con un X% de contenido duplicado no es más que otro mito de los SEO.
Ahora, posiblemente te estás preguntando: si Google no penaliza a los sitios web que tienen contenido duplicado, ¿De qué se trata todo este escándalo?
A pesar de que Google no penaliza a los sitios web por contenido duplicado, busca disuadirlos. Veamos por qué Google desalienta el contenido duplicado y después revisa las diferentes maneras de resolver los problemas de contenido duplicado en tu sitio web.
Antes de empezar, veamos cómo Google define contenido duplicado.
¿Qué es contenido duplicado?
Aquí tienes la definición de contenido duplicado según Google:
Contenido duplicado generalmente se refiere a bloques de contenido importantes dentro o entre dominios donde coincide completamente con otro contenido o son notablemente similares.
Como puedes entender desde la definición de Google, el buscador identifica dos tipos de instancias de contenido duplicado: el primer tipo que sucede en el mismo dominio y el otro tipo que sucede entre múltiples dominios.
Aquí tenemos algunos ejemplos para entender los distintos tipos.
Instancias de contenido duplicado en el mismo dominio
Como puedes ver, este tipo de contenido duplicado sucede dentro de tu sitio web.
Piensa en el contenido duplicado como el mismo contenido que aparece en diferentes lugares de tu web.
Podría ser:
- Un contenido que está presente en tu sitio web en diferentes locaciones (URL).
- O quizás es accesible a través de distintas maneras (por lo tanto resultan en diferentes URL). Por ejemplo, esto podría ser los mismos posts que se muestran cuando una búsqueda es realizada basada en diferentes categorías y etiquetas en tu sitio web.
Veamos algunos ejemplos de los diferentes tipos de contenido duplicado en el mismo sitio web.
Contenido Repetido:
Simplemente, el contenido repetido está disponible en diferentes secciones o páginas de tu sitio web.
Ann Smarty clasifica el contenido repetido como:
- (Todo el sitio web) navegación (inicio, sobre nosotros, etc.)
- Ciertas áreas especiales, específicamente si incluyen enlaces (blogroll, barra de navegación)
- Marcadores (javascript, CC id/nombres de clase como encabezado, pie de página)
Si observas un sitio web estándar, usualmente tendrá un encabezado, un pie de página y una barra lateral. Además de estos elementos, la mayoría de los CMS te permiten mostrar tus posts más recientes o lo más populares en tu página de inicio igualmente.
Cuando los bots de búsqueda rastrean tu sitio web, ellos verán que este contenido está presente varias veces en tu sitio web, por lo tanto, resulta ser un contenido duplicado dentro.
Pero este tipo de contenido duplicado no afecta el SEO. Los motores de búsqueda son lo suficientemente sofisticados para entender que la intención detrás de este contenido duplicado no es maliciosa. Así que estás a salvo.
Estructuras de URL inconsistentes:
Observa las siguientes URL:
www.yoursite.com/
yoursite.com
https://yoursite.com
https://yoursite.com/
¿Parecen iguales para ti?
Sí, tienes razón, la URL de destino es la misma. Así que para ti todas ellas significan lo mismo. Desafortunadamente, los bots de motores de búsqueda las leen como URL diferentes.
Sin embargo, cuando los bots de motores de búsqueda se encuentran con el mismo contenido en dos URL diferentes: https://yoursite.com and https://yoursite.com, las arañas consideran que es un contenido duplicado.
Este problema también se aplica para las URL generadas con fines de seguimiento igualmente:
https://yoursite.com/?utm_source=newsletter4&utm_medium=email&utm_campaign=holidays
Las URL con parámetros de seguimiento pueden causar problemas de contenido duplicado..
Dominios localizados:
Supongamos que atiendes a diferentes países y cuentas con dominios localizados creados para cada país que atiendes.
Por ejemplo, puede que tengas una versión .de de tu sitio web para Alemania y una versión .au para Australia.
Es normal que el contenido tenga algo en común en ambas webs. A menos que hayas traducido el contenido del dominio .de, los motores de búsqueda encontrarán el contenido como duplicado entre ambos sitios web.
En algunos casos, cuando un buscador esté buscando su negocio, Google le mostrará cualquiera de estos dos URL.
Google suele considerar el estado del buscador. Supongamos que el buscador se encuentra en Alemania. Google podría, por defecto, mostrar solamente tu dominio .de. Sin embargo, Google tal vez no lo haga bien.
Instancias de contenido duplicado en diferentes dominios
Contenido copiado:
El copiar contenido desde un sitio web (sin permiso) es incorrecto y Google así lo considera. Si sólo ofreces contenido duplicado, tu sitio web estará en riesgo. Google podría no mostrarlo en los resultados de búsqueda o quitar tu sitio web de las primera páginas de los resultados de búsqueda.
Curación de contenidos:
La curación de contenidos es el proceso de búsqueda de historias que resulten relevantes para tus lectores. Estas historias pueden ser de cualquier lugar en el Internet.
Desde que un post de curación de contenidos recopila un listado de piezas de contenido recogidos a través toda la web, es normal que los posts contengan contenido duplicado (incluso solo los títulos). La mayoría de los blogs comparten extractos y citas por igual.
De nuevo, Google no anota esto como SPAM.
A medida que proporciones alguna idea, una perspectiva nueva o expliques las cosas con tu propio estilo, Google no clasificará este contenido duplicado como malicioso.
Sindicación de Contenido:
La sindicación de contenidos se está convirtiendo en una técnica principal del marketing de contenidos. Curata descubrió que la mezcla ideal para el marketing de contenidos cuenta con una contribución del 10% de contenido sindicado.
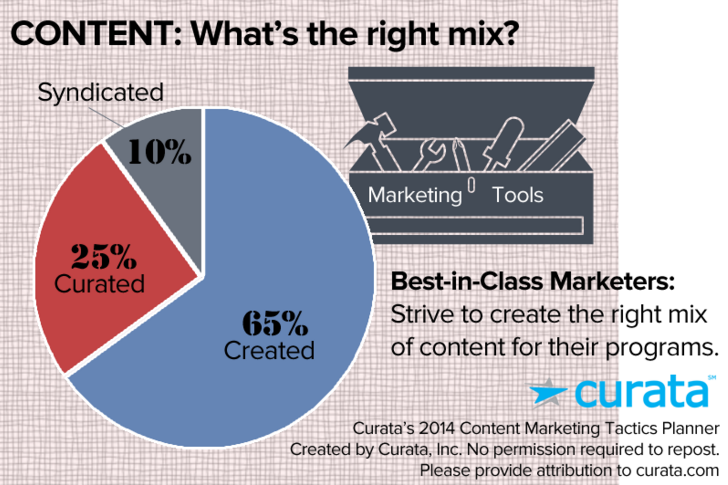
Como Search Engine Land ha publicado, “La sindicación de contenidos es el proceso de lanzar el contenido de tu blog, sitio web o vídeo dentro de sitios web de terceros, como un artículo completo, un fragmento, un enlace o una imagen en miniatura.”
Los sitios web que sindican contenidos ofrecen su contenido para ser publicado en varios sitios web. Esto significa que existen muchas copias de cualquier post sindicado.
Si estás familiarizado con el Huffington Post sabrás que permite la sindicación de contenido. Cada día incluye historias provenientes de toda la web y las republica con el debido permiso.
Buffer también sindica contenido. Su contenido es republicado en sitios web como Huffington Post, Fast Company, Inc. y muchos más.
Las siguientes capturas de pantalla muestran el tráfico que tal contenido sindicado trae al sitio web.
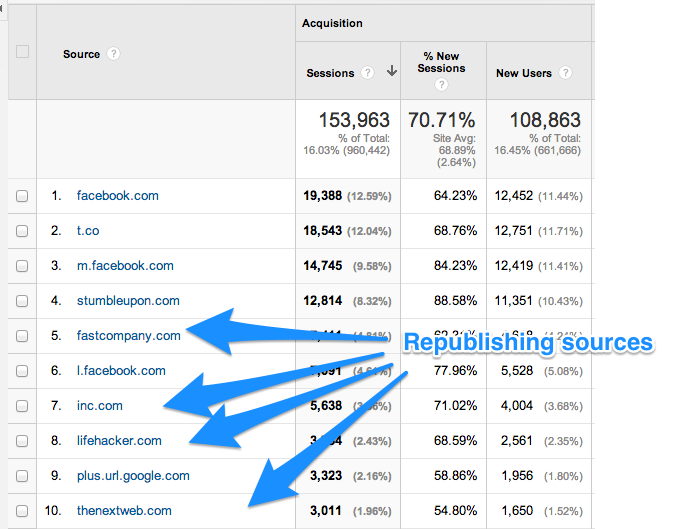
Aunque estas instancias son contadas como contenido duplicado, Google no los penaliza.
La mejor manera de sindicar contenido es solicitar a los sitios web que te republican es que te declaren como el creador original del contenido e igualmente el enlace directo a tu sitio, es decir, a la pieza original del contenido.
Contenido scraped:
La extracción de contenido (contenido scraped) siempre ha sido una zona gris cuando discutimos los problemas de contenido duplicado.
Wikipedia define la web scraping (o contenido scraped) como:
El web scraping (recolección de web o extracción de datos de web) es una técnica de software informático para extraer información de los sitios web.
Curiosamente, incluso Google extrae datos scraps datos para ofrecerlos inmediatamente sobre el primer SERP.
Por lo tanto, no resulta extraño el tuit de Matt Cutt,
Si ves un URL extraída de su fuente original en Google, por favor avísanos…
generando un poco de ruido.
Dan Barker respondió con este tuit:
@mattcutts Yo creo que he encontrado uno, Matt. Nota las similitudes en el texto:
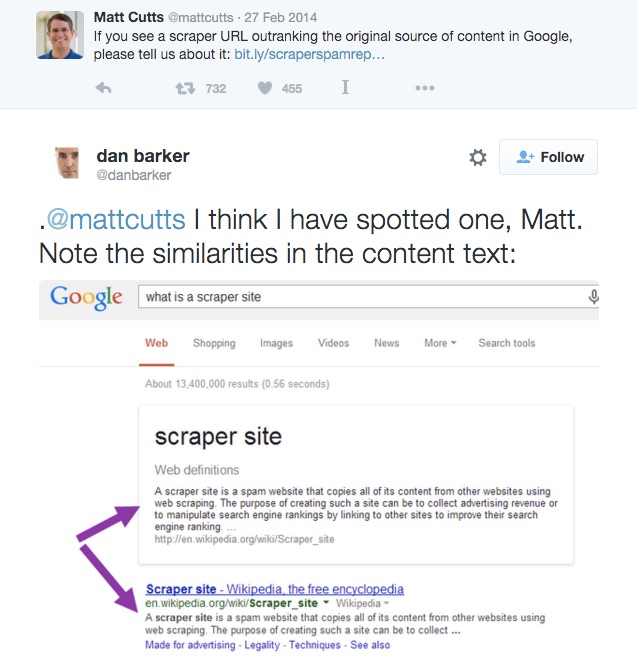
Como puedes ver, Google selecciona el contenido del primer resultado y lo muestra directamente en el SERP. Esto es, sin duda alguna, extracción de contenido.
Por lo tanto, descartamos la extracción de contenido como una negligencia que no será correcta en todos los casos.
Sin embargo, si indagas un poco más, verás que Google no tolera los sitios web que extraen contenido.
Ahora que tienes una idea razonable sobre qué implica el contenido duplicado, ahora veamos las instancias que no son casos de contenido duplicado, todavía los administradores de web se preocupan al respecto.
Aquello que no cuenta como contenido duplicado
Contenido traducido:
El contenido traducido NO es contenido DUPLICADO. Si tienes un sitio web y cuentas con localizaciones en diferentes países y traduces tu contenido principal en los idiomas locales, tú no te enfrentaras a ningún problema de contenido duplicado.
Pero, este ejemplo no es tan sencillo. Si usas algún software o incluso Google Traductor para la traducción, la calidad de la traducción no será perfecta.
Y si la traducción no tiene un sentido natural y carece de toque personal, Google puede considerar el contenido como spam y considerarlo contenido duplicado.
Dicho contenido puede identificarse fácilmente como que ha sido generado por un software y puede elevar así las alertas de Google.
La mejor manera de evitar este problema es conseguir un traductor humano para realizar el trabajo. O, realizar un trabajo decente con algún software destacado y luego que sea revisado por un traductor profesional.
Al verificar la traducción del contenido te aseguras que la calidad del contenido es de primer nivel y que Google no considera que es contenido duplicado.
Pero si por alguna razón no puedes realizar ninguna de estas dos opciones, entonces deberías bloquear los bots con los robots.txt para que no visiten el contenido traducido generado por el software. (Te mostraré cómo hacer esto en las siguientes secciones.)
Contenido de sitio web móvil:
Si no tienes un sitio web responsive, puede ser que hayas desarrollado un versión móvil separada para tu sitio web principal.
Por lo tanto, tienes diferentes URLs mostrando el mismo contenido, como por ejemplo:
http:yoursite.com – versión web
http:m.yoursite.com – versión móvil
Tener el mismo contenido en tu web y sitio web móvil no cuenta como contenido duplicado. Además, ya sabes que Google tiene diferentes bots de rastreo para sitios web como para los sitios móviles, así que no tienes que preocuparte por este caso.
Google puede identificar instancias de contenido duplicado que han sido realizadas con una intención maliciosa. Si no estás tratando de engañar al sistema, nunca estarás nunca en riesgo. Pero, igual debes evitar instancias de contenido duplicado ya que pueden afectar tu SEO.
Aquí tenemos cómo el contenido duplicado puede hacer sufrir a tu SEO:
Problemas causados por contenido duplicado
Problema #1 – Disolución de la popularidad del enlace
Cuando no estableces una estructura de URL consistente para tu sitio web, terminas creando y distribuyendo diferentes versiones de los enlaces de tu sitio web como al empezar el linkbuilding.
Para comprender esto de una manera mejor, imagina que has creado un contenido épico que ha producido una tonelada de enlaces inbound.
Sin embargo, no ves la autoridad de la página de esta fuente se incremente tanto como esperabas.
¿Por qué la autoridad de la página no se disparó, a pesar de todos los enlaces y la tracción ganada?
Tal vez sucedió porque los diferentes sitios web de backlinking lo enlazaron usando las diferentes versiones de URL del recurso.
Como:
https://www.yoursite.com/resource
https://yoursite.com/resource
https://yoursite.com/resource
y así continúa…
¿Ves cómo el contenido duplicado arruina tus opciones de crear una página de autoridad alta?
Todo esto debido a que los motores de búsqueda no pueden interpretar que todos los URL apuntan a la misma locación.
Problema #2 – Mostrando URL hostiles
Cuando Google se encuentra con dos recursos idénticos o que se parecen similares en la web, se elige mostrar uno de ellos al buscador. En la mayoría de los casos, Google seleccionará la versión más apropiada de tu contenido. Sin embargo, no siempre lo hace de forma correcta.
Puede que suceda que en una búsqueda particular Google no te muestre la mejor versiónde la URL.
Por ejemplo, si el buscador está buscando tu negocio online, cuál de las siguientes opciones te gustaría que se mostrará al visitante:
https://yoursite.com
o https://yoursite.com/overview.html
Yo creo que estarías interesado en que mostrara la primera opción.
Sin embargo, Google puede que muestre la segunda opción.
Si hubieses evitado el contenido duplicado en primer lugar, no habría esta confusión y el usuario solo vería la mejor y más cualificada versión de tu URL.
Problema #3 – Haciendo zapping en los recursos de los motores búsqueda
Si te entiendes cómo funcionan los crawlers, sabrás que Google envía sus bots de búsqueda a rastrear tu sitio web dependiendo de la frecuencia de tu publicación de contenido nuevo .
Ahora, imagina que los rastreadores de Google visitan tu sitio web y encuentran cinco URL que ofrecen el mismo contenido.
Cuando los bots de búsqueda descubren e indican la existencia del mismo contenido en diferentes lugares de tu sitio web, pierdes los ciclos de rastreo.
Estos ciclos de rastreo podrían haber sido usados para rastrear e indexar cualquier contenido nuevo que puedas haber publicado en tu sitio web. Esto no sería una pérdida de recursos de rastreo sino que también afectará a tu SEO.
Cómo Google maneja el contenido duplicado
Cuando Google encuentra instancias de contenido idéntico, decide mostrar uno de ellos. La elección del recurso que muestre en la búsqueda dependerá de la necesidad de la consulta.
Si tienes el mismo contenido en tu sitio web y ofreces una versión impresa también, Google considerará si el buscador está interesado en la versión impresa. Si es así, sólo será presentada la versión impresa del contenido.
Puede que hayas visto mensajes en el SERP indicando que otros resultados similares no fueron mostrados. Esto sucede cuando Google selecciona una de las varias copias de contenido similar.
El contenido duplicado no siempre es tratado como SPAM. Se convierte en un problema sólo cuando busca abusar, engañar y manipular los motores de búsqueda.
Google se toma en serio el contenido duplicado e incluso puede prohibir tu sitio web si tratas de engañar al motor de búsqueda usando el contenido duplicado.
Las políticas de contenido duplicado de Google establecen:
En los extraños casos en los que Google perciba que el contenido duplicado puede ser mostrado con la intención de manipular nuestras clasificaciones y engañar a nuestros usuarios, nosotros haremos los ajustes pertinentes para indexar y clasificar a los sitios involucrados. Como resultado de esto, la clasificación del sitio web podría verse afectada, o el sitio web podría ser borrado completamente de la indexación de Google, caso en el que no aparecerá más en los resultados de búsqueda.
Como viste anteriormente, la mayoría de las instancias de contenido duplicado no suceden de manera intencionada. Incluso podrías estar usando contenido repetido en tu sitio web. Además, puede ser que los diferentes sitios web estén copiando y re-publicando tu contenido sin tu permiso.
Existen diferentes maneras a través de las que puedes revisar tu sitio buscando problemas de contenido duplicado. Veamos algunas opciones.
Cómo identificar los problemas de contenido duplicado
Método #1: Realizar una sencilla búsqueda en Google
Una sencilla manera de detectar los problemas de contenido duplicado de tu sitio web es hacer una sencilla búsqueda en Google.
Busca una palabra clave que hayas posicionado y observa los resultados en los motores de búsqueda. Si encuentras que Google está mostrando una URL no friendly de tu contenido, entonces tienes contenido duplicado en tu sitio web.
Método #2: Observa las alertas en los administradores web de Google
La Consola de Búsqueda de Google genera alertas sobre las instancias de contenido duplicado en tu sitio web.
Para conseguir las alertas de Google sobre contenido duplicado entra en tu cuenta de Google Webmasters. Si ya estás adentro, puedes hacer clic en este enlace.
Método 3: Revisa los parámetros de rastreo en tu panel de instrumentos de Webmasters
Los parámetros de rastreo muestran el número de páginas que Google rastreo en tu sitio web.
Si ves crawlers rastreando e indexando cientos de páginas en tu sitio web mientras que tienes unas pocas, posiblemente estés usando URL inconsistentes. Y, por lo tanto, los rastreadores de los motores de búsqueda están rastreando el mismo contenido varias veces en diferentes URL.
Para ver los Parámetros de rastreo, ingresa a tu cuenta de Google Webmasters, haz clic en la opción de Rastreo en el panel a la izquierda. Bajo el menú desplegable, haz clic en la opción de Estadísticas de Rastreo.
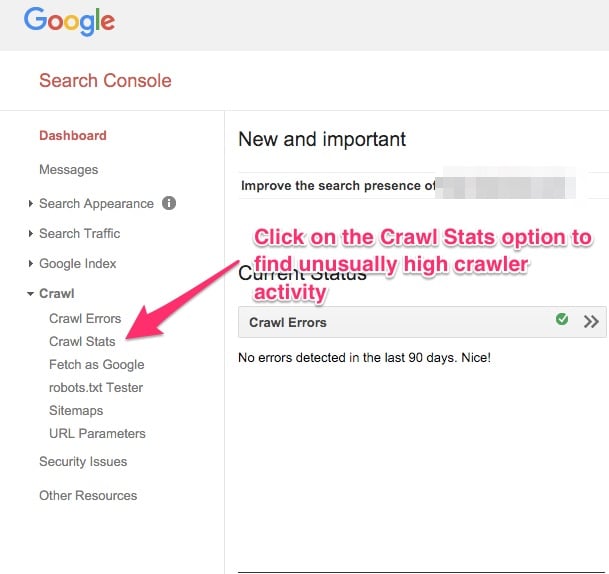
Si ves una actividad de rastreo inusualmente alta debes revisar la estructura de tu URL y ver si tu sitio web está usando URL inconsistentes.
Método 4: Screaming Frog
Screaming Frog es una herramienta de escritorio para auditoria de SEO que rastrea tu sitio web como los rastreadores. Con esta herramienta puedes identificar los diferentes tipos de problemas de contenido duplicado.
Pasos para usar Screaming Frog para encontrar problemas de contenido duplicado:
1. Visita el sitio web oficial de Screaming Frog y descarga una copia que sea compatible con tu sistema.
Por favor recuerda que la versión gratuita de Screaming Frog puede ser usada para rastrear hasta 500 páginas. Esto es suficiente para la mayoría de los casos.
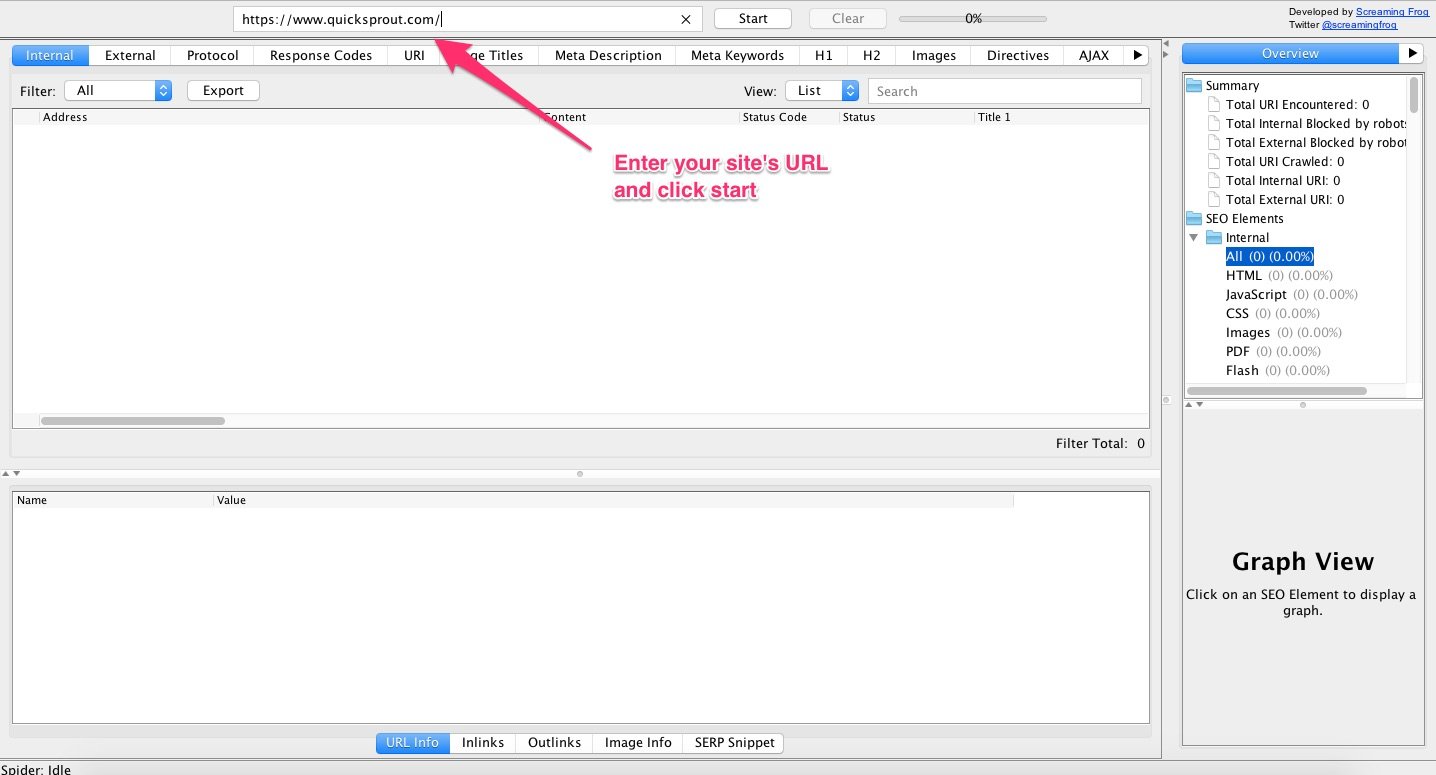
2. Una vez que hayas instalado el programa, ábrelo e ingresa la URL de tu sitio web. Haz clic en start.
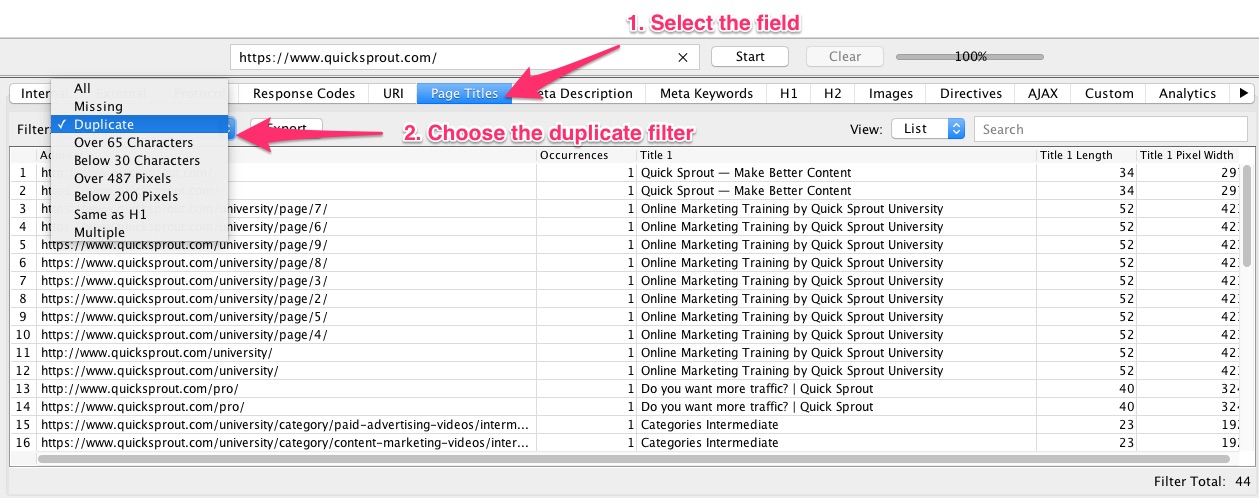
3. Una vez que Screaming Frog rastree tu sitio web, puedes hacer clic en el campo que desees revisar el contenido duplicado, como por ejemplo URL, títulos de página, metadescripción y mucho más.
Después de seleccionar el campo, elige el filtro de duplicado. Usando este método, puedes detectar todos los casos de contenido duplicado en tu sitio web.
Método 5: Búsqueda en bloques de contenido
Este método resulta un poco rudimentario, pero si tienes alguna sospecha de que tu contenido está siendo copiado en varios sitios web o está ubicado en diferentes lugares de tu sitio web, podrías usar este método.
Copia cualquier bloque de texto desde tu contenido y simplemente búscalo en Google. Recuerda no usar párrafos muy largos ya que generará un error en la búsqueda.
Elige dos o tres frases del párrafo y búscalas en Google.
Si los resultados de búsqueda muestran diferentes sitios web con tu contenido publicado, probablemente esté siendo víctima de un plagio.
Utilizando los métodos anteriormente mencionados, puedes identificar fácilmente los problemas de contenido duplicado en tu sitio web. Ahora veamos algunas soluciones para manejar los problemas de contenido duplicado.
4 soluciones para tratar los problemas de contenido duplicado
1. Consistencia
Tal y como viste en la sección anterior, la mayoría de las instancias de contenido duplicado son consecuencia de una estructura URL inconsistente.
La mejor solución para este caso es estandarizar tu estructura de enlaces preferente. Podría ser la versión www o la versión sin www. O quizás la versión HTTP o HTTPs, cualquiera que elijas necesita ser consistente.
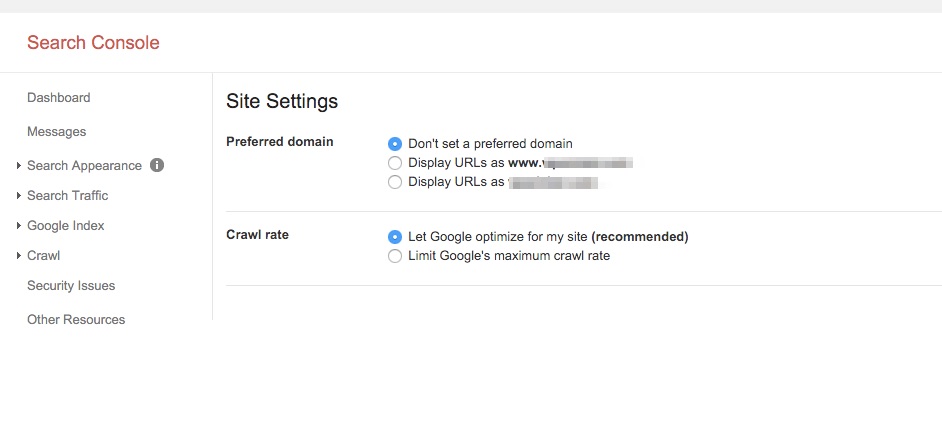
Puedes comunicar a Google tu versión URL preferida al establecerla en tus preferencias en tu cuenta de Google Webmasters.
Después de acceder, haz clic en el icono de configuración en la esquina superior derecha. Selecciona Configuraciones de Sitio Web.
Aquí puedes ver las opciones para establecer tu dominio preferido:
Los beneficios de establecer un dominio preferido son:
- Los problema de contenido duplicado con la versión www y sin www
Ahora que sabes que los bots de Google tratan a yoursite.com y a www.yoursite.com como dos páginas diferentes y el contenido de ambas es considerado como contenido duplicado.
Con simplemente establecer tu dominio preferido, puedes solicitarle a Google sólo rastrear e indexar una de ella y al mismo tiempo eliminas la posibilidad de riesgo por contenido duplicado.
- Conservar link juice
La configuración de un dominio preferente ayuda a tu web a mantener los link juice incluso cuando haya un sitio web de backlinking que enlace a una versión no preferente de tu sitio web.
Un fragmento de la fuente de Google:
Por ejemplo, en caso de especificar un dominio preferente como https://www.example.com y encontramos un enlace a tu sitio web como https://example.com, rastrearemos el enlace como https://www.example.com
Además, tendremos en cuenta tu preferencia a la hora de mostrar las URL. En caso de no especificar un dominio, podemos tratar las versiones www y sin www del dominio como referencias separadas de distintas páginas.
La opción de preferencia de dominio de Google cuidada mucho las inconsistencias con la versión www y la no www de tu sitio web.
Después de establecer tu dominio preferido en las herramientas de Google Webmaster, tu siguiente paso debería ser establecer redirecciones 301 desde los enlaces no preferidos en tu sitio web hasta tus preferidos. Esto te ayudará a que los motores de búsqueda y visitantes aprendan sobre tu versión preferida.
Sin embargo, pueden existir otras inconsistencias mencionadas anteriormente. Para dilucidar estas cuestiones no deberías sólo seleccionar una versión preferente de URL, sino que también deberías establecer la sintaxis exacta que tu equipo usara cuando enlacen cualquier contenido a tu sitio web.
Igualmente, puedes tener una guía de estilos que puede ser distribuida de manera interna para mostrar las maneras estándar para compartir URL. Básicamente, cuando compartes un enlace a cualquier página o publicación en tu sitio web deberías poder estar seguro que el enlace que salga siempre tiene el mismo formato.
Recuerda que los motores de búsqueda pueden tratar estos contenidos de manera distinta: https://www.yoursite.com/page/ , https://www.yoursite.com/page y https://www.yoursite.com/page/index.htm. Así que escoge uno y mantenlo constante.
2. Canonicalización
La mayoría de los CMS te permiten organizar tu contenido usando etiquetas y categorías. Usualmente cuando los usuarios realizan búsquedas de etiquetas o basadas en categorías, se muestra el mismo resultado. Como un resultado, los bots de los motores de búsqueda pueden pensar que ambos de las URL ofrecen el mismo contenido.
https://www.yoursite.com/some-category
y
https://www.yoursite.com/some-tag
Este problema resulta mucho más serio en sitios web de comercio electrónico donde un único producto puede ser mostrado usando diferentes filtros (esto resulta en muchos URL).

Es cierto que estas categorías, etiquetas, filtros y cajas de búsqueda te ayudan a organizar tu contenido y a hacerle más fácil a tus visitantes encontrar lo que necesitan.
Pero, como puedes apreciar en las capturas de pantalla anteriores, cuyo resultado de búsqueda se encuentra en múltiples URL y esto es lo que causa contenido duplicado.
Cuando las personas buscan contenido en Google, estos múltiples enlaces pueden generar confusión en los bots de Google y Google puede terminar mostrando una versión poco amigable de tu recurso, como por ejemplo https://www.yoursite.com/?q=search en los resultados de búsqueda.
Para evitar este problema, Google recomienda que agregues una etiqueta canónica para la URL preferente de tu contenido.
Cuando un bot del buscador a va a una página y nota la etiqueta canónica, obtiene el enlace de la fuente original. Además, todos los enlaces a cualquier página duplicada son contados como enlaces a la página original. Así que no pierdes ningún valor de SEO con esos enlaces.
Las urls canónicas puede ser implementada de diferentes maneras:
Método 1: Establecer la versión preferida: con www y sin www
Establecer una versión preferente de tu dominio, como hemos discutido en la sección anterior, es una forma de canonicalización.
Sin embargo, como entenderás, esto se refiere a un problema muy amplio. No maneja el contenido duplicado que generan los CMS.
Método 2: Establecer manualmente el enlace canónico en todas las páginas
En este método, deberías empezar definiendo tu recurso original. El recurso original es la página que quieres que esté disponible para tus lectores cada vez que ellos la busquen.
El recurso original ademas es la página que tu quieres establecer como tu página preferente para indicar a los bots de los motores de búsqueda.
Usa los métodos mencionados en la sección anterior para identificar las instancias de contenido duplicado en tu sitio web. Después, identifica las páginas que ofrecen un contenido similar y elige el recurso original para cada una de ellas.
Después de los dos pasos anteriores, estás listo para usar la etiqueta canónica.
Para hacerlo, tienes que ingresar el código de fuente del recurso, dentro de esta etiqueta <head> , agregando la siguiente línea:
<link rel=»canonical» href=»https://yoursite.com.com/category/resource» />
Aquí, «https://yoursite.com.com/category/resource» es la página que quieres denominar como el recurso original.
Seguirás el mismo proceso sobre en página similar.
Mi blog en las categorías de soporte de CrazyEgg . Los posts son accesibles desde la lista de enlaces así como a través de las diferentes categorías.
Yo uso la etiqueta rel=canonical para marcar mi URL preferida para cada página y post.
Observa las siguientes capturas de pantalla mostrando la etiqueta:

Usar las etiquetas canónicas es una manera sencilla de comunicarle a Google el enlace que te gustaría que mostrara a los usuarios que buscan.
Probablemente puedes decirme: mi sitio web está construido sobre WordPress y estoy usando el plugin Yoast SEO. Este plugin te permite configurar la versión preferida tanto en página como en post. Por lo tanto, no tienes que preocuparte sobre si tus publicaciones y sus URLS son accesible o si se muestran en diferentes direcciones URL.
Si su sitio está construido sobre WordPress, te recomiendo que instales este plugin. Se puede encontrar la opción de URL canónica debajo de la configuración avanzada del plugin.
Si un post o una página que creaste es en sí la versión preferida, deja el espacio en blanco para etiqueta URL canónica. Si no es así, añade un enlace al recurso preferido en el campo URL canónica.
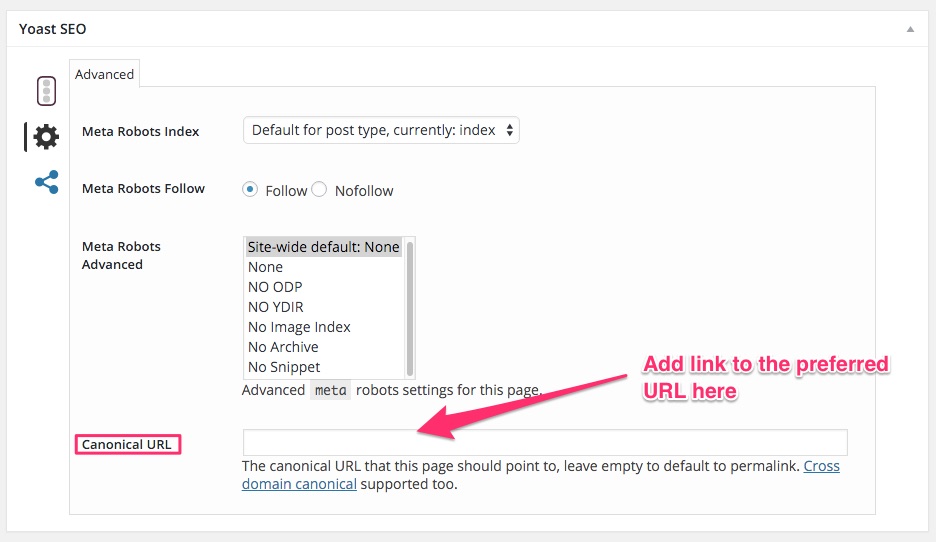
Método 3: Establece redirecciones 301
A menudo, la restructuración de sitios web conlleva problemas de contenido duplicado. Reestructurar el formato de un enlace también puede crear múltiples copias del mismo contenido.
Para reducir el impacto de estos problemas, establece redirecciones 301. Las redirecciones 301 desde los URL no preferidos del recurso hasta sus URL preferidos son una gran manera de alertar a los motores de búsqueda sobre tus preferencias. .
Cuando un bot de un buscador va a una página y ve redirecciones 301, llega al recurso original a través del contenido duplicado de la página. En tales casos, todos los enlaces a las página duplicadas son tomados como enlaces a la página original (no hay perdida de SEO).
Dependiendo de tu sitio web, podrías usar estas diferentes maneras de establecer redirecciones 301. Si tienes alguna pregunta sobre establecer redirecciones, tu webhost debería estar disponible para ayudar.
Si usas WordPress, puedes usar un plugin llamado Redirección para crear redirecciones 301.
Independientemente del método que decidas usar, te sugiero que hagas una prueba para enlaces rotos antes de que la configuración de redirecciones se realice mal.
3. Meta etiqueta noindex
Las meta etiquetas son un medio para que los webmasters den a los motores de búsqueda información relevante sobre sus sitios web.
La meta etiquetas noinde le comunican a los bots de motores de búsqueda que no indexen a un recurso particular.
Las personas confunden con frecuencia la meta etiqueta noindex con la nofollow. La diferencia entre ellos es que cuando usas las etiquetas noindex y nofollow, estás pidiendo a los motores que ni indexen y ni sigan la página.
Mientras que cuando usas las etiquetas noindex y follow, estás solicitando a los motores de búsqueda no indexar la página pero no ignorar cualquier enlace de/a la página.
Puedes usar la meta etiqueta noindex para evitar tener a los motores de búsqueda indexando las páginas con contenido duplicado.
Para usar la meta tag para manejar las instancias de contenido duplicado, deberías agregar la siguiente línea de código en la etiqueta de tus páginas de contenido duplicado.
<Meta Name=”Robots” Content=”noindex,follow”>
Usando la etiqueta follow en conjunto con la etiqueta noindex asegura que los motores de búsqueda no ignoren los enlaces en las páginas duplicadas.
4. Usa la etiqueta hreflang para controlar los sitios web localizados
Cuando usas contenido traducido, debes usar una etiqueta hreflang para ayudar a los motores de búsqueda a seleccionar la versión correcta de tu contenido.
Si tienes un sitio web en inglés y lo has traducido al español para dirigirlo a la audiencia local, deberías agregar la etiqueta, “<link rel=»alternate» href=»https://example.com» hreflang=»en-es» />” para la versión en español de tu sitio web.
Deberías seguir el mismo proceso para todas las diferentes versiones localizadas de tu sitio web. Esto eliminará el riesgo de que los motores de búsqueda lo consideren como contenido duplicado y además mejorará la experiencia del usuario cuando quieran interactuar en tu sitio web en su idioma nativo.
5. Usa el hashtag en lugar del signo de interrogación cuando uses los parámetros UTM
Es habitual usar parámetros de seguimiento como la fuente, campaña y medio para medir la eficiencia de los diferentes canales.
Sin embargo, tal y como hemos visto anteriormente, cuando creas un enlace como https://yoursite.com/?utm_source=newsletter4&utm_medium=email&utm_campaign=holidays, los motores de búsqueda lo rastrean y reportan las instancias de contenido duplicado.
Una solución sencila contra ello es usar el hashtag en lugar del signo de interrogación. Cuando los motores de búsqueda se encuentran con un signo # en un URL ignoran todo lo que sigue detrás del símbolo, evitando así los problemas de contenido duplicado.
6. Ten cuidado con la sindicación de contenido
Si le permites a diferentes sitios web republicar tu contenido, pídeles siempre que pongan el enlace de vuelta a tu sitio web. Pedir que los sitios web que al publicar tu contenido usen la etiqueta rel o la etiqueta noindex podría igualmente ayudarte a prevenir problemas de contenido duplicado causados por la reedición del contenido.
Cómo no lidiar el contenido duplicado
Como he venido diciendo, el contenido duplicado ocurre todo el tiempo. Si encuentras que tu sitio web contiene cualquier instancia de contenido duplicado, debes corregirlo. Ya te he mostrado diferentes maneras de hacerlo.
Sin embargo, ahora me gustaría mostrarte algunas maneras de corregir los problemas de contenido duplicado que no son correctas y que no deberían ser usadas.
1. No bloquees las URL con robots.txt
Ante todo, ¿Qué es el robots.txt? El robots.txt es un archivo de texto que tiene mensajes que quieres comunicar a los rastreadores. Estos mensajes podrían ser solicitados para que los rastreadores no indexen determinados URL.
Algunos webmasters especifican URLs que contienen contenido duplicado en los archivos Robot.txt y, por lo tanto, tratan de bloquear los motores de búsqueda del rastreo.
Google desaconseja todas aquellas prácticas que bloquean los rastreadores de alguna manera. Cuando las páginas bloquean el rastreo, los robots de Google las cuentan como páginas únicas, aunque en realidad no son páginas únicas, sino que simplemente son páginas con contenido duplicado.
El segundo problema con este tipo de bloqueo es que otros sitios todavía pueden ser capaz de enlazar a una página bloqueada. Si un sitio de alta calidad enlaza a una página bloqueada y los robots de los motores de búsqueda no rastrean la página, no obtendrás el beneficio de SEO de ese backlink.
Además, siempre se pueden marcar páginas duplicadas como duplicado utilizando la etiqueta «canónica».
2. No gires (ni reformules) el contenido para hacerlo “único”
Los bots de Google pueden decir si tu contenido está modificado o generado por un bot. Así que, modificar el contenido o sólo reformularlo para hacerlo parecer único no te ayudará.
Publicar contenido modificado indicará a los motores de búsqueda que estás usando técnicas sospechosas para manipular las clasificaciones de búsqueda. Esto podría hacer que Google tomara acciones en contra tu sitio web.
3. No uses la opción de “eliminar URL” en Google Webmasters
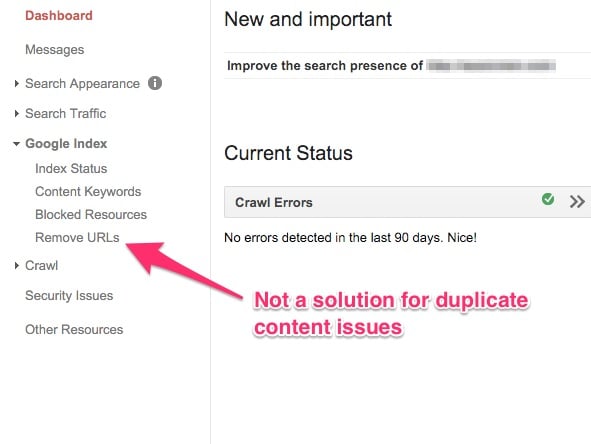
Si te has dado cuenta, Google Webmasters le da la opción de eliminar las URL de su sitio.
Por lo tanto, algunos webmasters deciden elegir una versión no amistosa del recurso que aparece en los resultados de búsqueda y lo eliminan utilizando la opción anterior.
El problema con esta solución es que las URL solamente se eliminan temporalmente. Y el sitio tendrá que enfrentarse a todos los problemas que he mencionado anteriormente. Esta no es una solución.
Esta característica es útil cuando deseas eliminar algo de tu sitio y deseas una solución rápida hasta que se pueda trabajar en el sitio para resolverlo. No ayuda con problemas de contenido duplicado.
Conclusión
La mayoría de los problemas de contenido duplicado pueden ser evitados y corregidos.
¿Has comprobado si tu sitio web tiene problemas de contenido duplicado? Si es así, ¿Qué métodos usarás para resolverlos?

See How My Agency Can Drive More Traffic to Your Website
- SEO – unlock more SEO traffic. See real results.
- Content Marketing – our team creates epic content that will get shared, get links, and attract traffic.
- Paid Media – effective paid strategies with clear ROI.