



As pessoas amam “atalhos”.
Eu também – adoro encontrar maneiras de facilitar a minha vida e torná-la melhor.
É por isso que a técnica que vou te apresentar hoje é uma das minhas favoritas de todos os tempos. É um atalho SEO legítimo que você pode começar a usar de imediato.
É uma maneira de melhorar o seu SEO fazendo uso de uma parte essencial de todo site que não costuma ser abordada. Também não é difícil de implementar.
É o arquivo robots.txt (também conhecido como protocolo ou padrão de exclusão de robôs).
Esse pedaço de arquivo de texto é parte de todo site na internet, mas a maior parte dos usuários nem o conhece.
É feito para trabalhar com ferramentas de busca, mas é, surpreendentemente, um combustível para SEO esperando ser queimado.
Já tive muitos clientes tentando de tudo para melhorar seus SEO. Quando conto que sobre a edição do arquivo de texto, eles custam a acreditar.
Entretanto, existem muitos métodos de melhorar SEO que não são difíceis ou tomam tempo, e esse é um deles.
Você nem precisa ter nenhuma experiência técnica para aproveitar as vantagens do robots.txt. Se você tem acesso ao código-fonte do seu site, você pode aproveitar.
É só seguir comigo quando estiver pronto. Vou te mostrar como modificar o seus arquivos robots.txt para que as ferramentas de busca passem a amar o seu site.

Veja como minha agência pode aumentar drasticamente o tráfego do seu site
- SEO - Desbloqueie um volume enorme de tráfego através do SEO. Veja resultados reais.
- Marketing de Conteúdo - Nosso time cria conteúdo épico que vai ser compartilhado, linkado, e vai atrair tráfego.
- Mídia Paga - Estratégias de anúncios efetivas e com ROI claro.
Aprenda como melhorei meu SEO para gerar um adicional de 195.013 visitantes por mês.
Uma forma eficiente de gerar tráfego para seu site a longo prazo é usando SEO. Se você quer aumentar o tráfego do seu site e atrair mais usuários qualificados e clientes, clique aqui e receba o Guia Completo de SEO.

Por que o arquivo robots.txt é importante?
Antes de mais nada, é bom saber porque o arquivo robots.txt tem tanta importância.
Também conhecido como protocolo ou padrão de exclusão de robôs, é um arquivo de texto que avisa aos robôs da internet (quase sempre ferramentas de busca) quais páginas do seu site rastrear.
Também avisa quais páginas ignorar.
Digamos que uma ferramenta de busca está prestes a visitar um site. Antes de chegar na página procurada, vai checar os robots.txt para instruções.
Existem tipos diferentes de arquivos robots.txt, vamos saber mais sobre cada um.
Por exemplo, a ferramenta de busca vai encontrar este exemplo de arquivo robots.txt:

Esse é o esqueleto básico de um arquivo robots.txt.
O asterisco depois de “user-agent” indica que o arquivo robots.txt se aplica a todo tipo de robô da internet que visita o site.
A barra depois de “Disallow” informa ao robô para não visitar nenhuma das páginas do site.
Talvez você esteja se perguntando porque alguém iria querer impedir a visita de robôs da internet a seus sites.
Desbloqueie milhares de palavras-chave com Ubersuggest
Quer superar a concorrência?
- Encontre palavras-chave de cauda longa com alto ROI
- Encontre centenas de palavras-chave
- Transforme buscas em visitas e conversões
Ferramenta gratuita
Afinal de contas, um dos principais objetivos de SEO é atrair ferramentas de busca para o seu site e aumentar o seu ranking.
E é aí que o secreto desse atalho de SEO aparece.
Desbloqueie milhares de palavras-chave com Ubersuggest
Quer superar a concorrência?
- Encontre palavras-chave de cauda longa com alto ROI
- Encontre centenas de palavras-chave
- Transforme buscas em visitas e conversões
Ferramenta gratuita
É possível que você tenha muitas páginas em seu site, certo? Mesmo que você ache que não, dê uma checada. Você vai se surpreender.
Se uma ferramenta de busca rastrear o seu site, vai rastrear cada uma das páginas.
E se você tem muitas páginas, o robô da ferramenta de busca vai tomar mais tempo para verificar o seu site, o que pode ter um efeito negativo no seu ranqueamento.
Isso é porque o Googlebot (o robô da ferramenta de busca do Google) tem um “limite de rastreamento”.
Esse limite pode ser resumido em duas partes. É a primeira é o limite da taxa de rastreamento. Veja a explicação do Google:

A segunda parte é demanda de rastreamento:

Limite de rastreamento é, basicamente, o “número de URLs que o Googlebot pode e quer rastrear”.
O ideal é auxiliar o Googlebot a gastar o seu limite de rastreamento da melhor maneira possível. Em outras palavras, rastrear as suas páginas de maior valor.
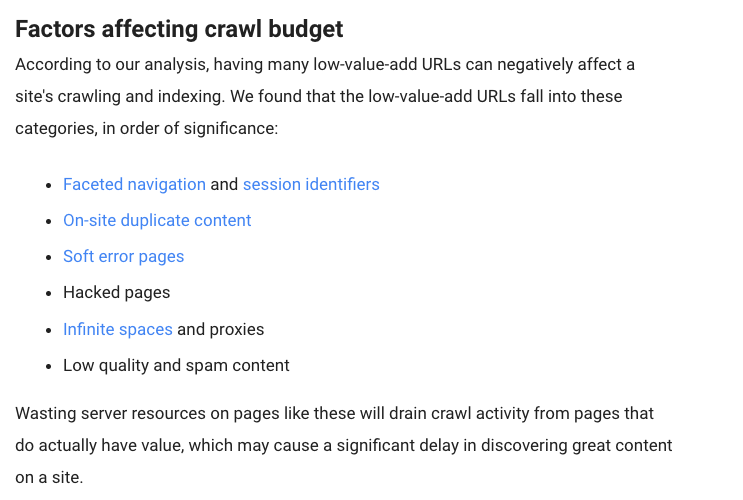
Existem alguns fatores que irão, de acordo com o Google, “afetar negativamente o rastreamento e indexação de um site”.
Os fatores são estes:
Vamos voltar para o robots.txt.
Se você criar a página robots.txt corretamente, você pode avisar aos robôs das ferramentas de busca (e especialmente ao Googlebot) quais páginas evitar.
Considere as implicações. Se você avisa aos robôs das ferramentas de busca que elas devem rastrear apenas seu conteúdo mais útil, os robôs irão rastrear e indexar somente esse conteúdo.
“É bom evitar sobrecarregar o seu servidor com o rastreador do Google ou desperdiçar limite de rastreamento com páginas sem importância do seu site.”
Ao usar robots.txt da maneira correta, você pode avisar aos robôs das ferramentas de busca como gastar bem o limite de rastreamento. E é por isso que o arquivo robots.txt é tão útil no contexto de SEO.
Curioso para conhecer mais do poder do robots.txt? Ótimo! Vamos falar mais sobre como achar e usar.
Encontrando o seu arquivo robots.txt
Existe um jeito fácil de dar só uma olhada rápida em seus arquivos robots.txt.
E é um método que funciona para qualquer site. Dá para espiar arquivos de outros sites e ver como estão fazendo.
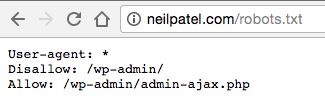
É só digitar a URL base do site na barra de endereços do navegador (como neilpatel.com, quicksprout.com, etc.) e adcionar /robots.txt ao final.
Uma das três situações seguintes vai acontecer:
1) Você vai achar um arquivo robots.txt.
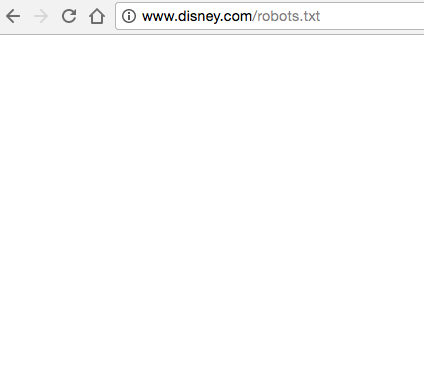
2) Você vai achar um arquivo vazio.
Por exemplo, parece que o site da Disney não tem arquivos robots.txt:
3) Você vai achar um 404.
O site do Method responde por robots.txt com um 404:
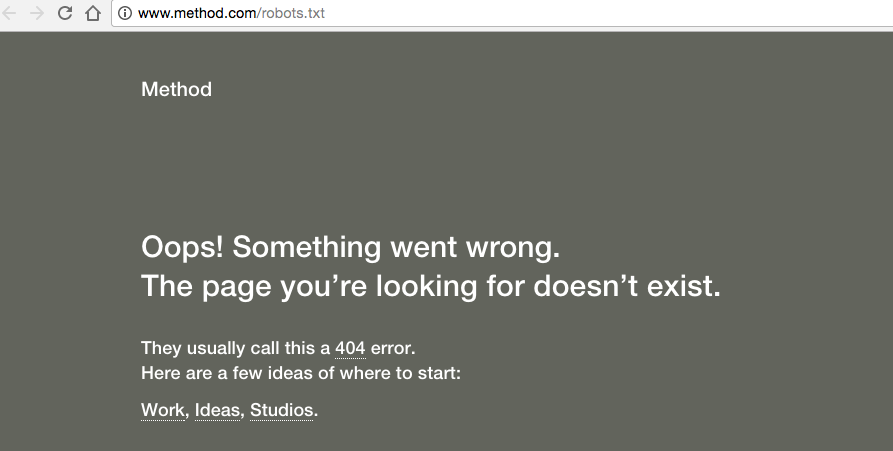
Verifique o arquivo robots.txt do seu próprio site.
Se encontrar um arquivo vazio ou um 404, é bom consertar.
Caso encontre um arquivo válido, está com as configurações padrões de quando o seu site foi criado.
Gosto especialmente desse método de procurar pelos arquivos robots.txt em outros sites. Depois de aprender as técnicas desse arquivo, esse pode ser um exercício vantajoso.
Agora vamos ver como modificar os seus arquivos robots.txt.
Encontrando o seu arquivo robots.txt
Os próximos passos vão depender de você ter ou não arquivo robots.txt. (Confira usando o método descrito acima.)
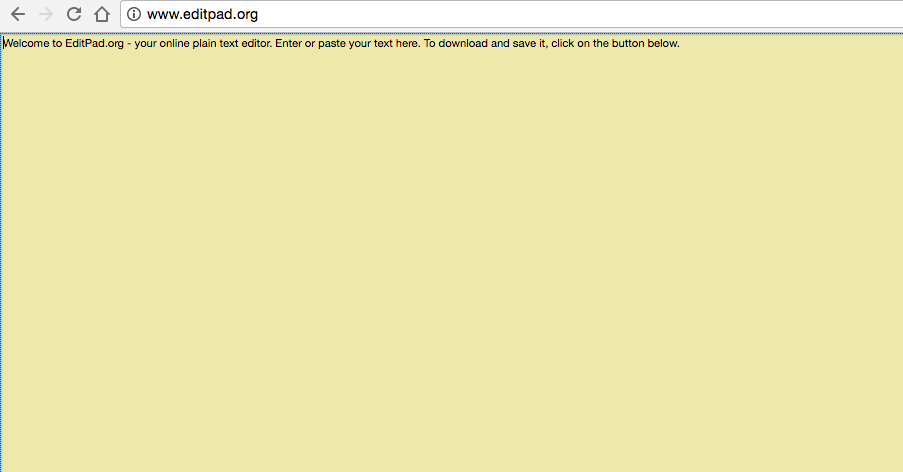
Caso não tenha um, vai precisar criar do zero. Abra um editor de texto simples, como o Notepad (Windows) ou TextEdit (Mac).
Use apenas um editor de texto simples. Caso use programas como o Microsoft Word, códigos adicionais podem ser inseridos no texto.
Editpad.org é uma ótima opção gratuita, e é essa que vou usar neste artigo.
De volta ao robots.txt. Se você tem um arquivo robots.txt, vai precisar localizá-lo no diretório central do seu site.
Caso não esteja acostumado a vasculhar um código-fonte, talvez tenha um pouco de dificuldades em localizar a versão editável do seu arquivo robots.txt.
Normalmente, você vai encontrar o seu diretório central entrando no site da sua conta de servidor e indo até o gerenciador de arquivos ou a seção FTP de seu site.
Você verá algo parecido com isto:
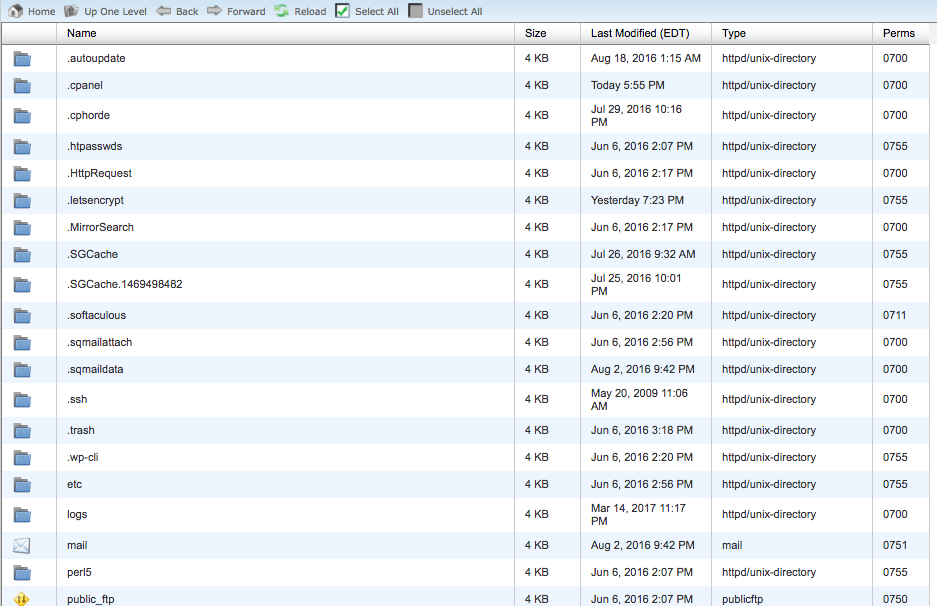
Encontre e abra os seus arquivos robots.txt para editá-los. Delete todo o texto, mas mantenha os arquivos.
Atenção: caso esteja usando WordPress, talvez veja um arquivo robots.txt ao ir em seusite.com/robots.txt, mas não vai encontra-lo em seus arquivos.
Isso é porque o WordPress cria um arquivo robots.txt virtual caso não existe robots.txt no diretório central.
Caso isso aconteça, você vai precisar criar um novo arquivo robots.txt.
Criando um arquivo robots.txt
Você pode criar um novo arquivo robots.txt usando o editor de texto simples de sua preferência (e somente um editor de texto simples).
Se você já tem um arquivo robots.txt, certifique-se de deletar o texto (mas não o arquivo).
Primeiro, você vai precisar conhecer melhor a sintaxe usada num arquivo robots.txt.
Google tem um boa explicação de algumas noções básicas de termos robots.txt:
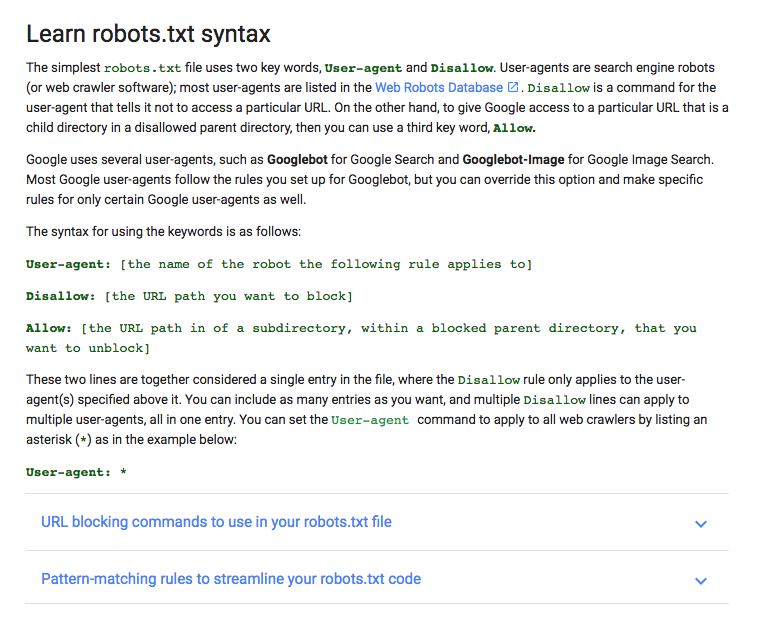
Vou mostrar como criar um simples arquivo robots.txt, depois, vamos aprender como customizá-lo para SEO.
Inicie configurando o termo user-agent. Vamos configurar para que possa se aplicar a todos os robôs da internet.
Para fazer isso, é só usar um asterisco depois do termo user-agent, assim:

A seguir, digite “Disallow:”, e mais nada depois disso.

Já que não há nada depois de “disallow”, os robôs da internet vão rastrear todo o seu site. Por enquanto, tudo em seu site está ao alcance deles.
O seu arquivo robots.txt deve estar assim no momento:

Parece muito simples, mas essas duas linhas já estão fazendo muito.
Você também pode linkar para o seu mapa de site XML, mas não é obrigatório. Caso queria, é só digitar:
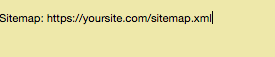
Acredite ou não, mas isso é um arquivo básico de texto robots.txt.
Vamos avançar para o próximo nível e transformar esse pequeno arquivo em uma turbina SEO.
Otimizando robots.txt para SEO
Como você otimiza robots.txt depende do conteúdo que você tem em seu site. Existem mil maneiras de tirar vantagens de robots.txt.
Vou falar das mais comuns.
(Tenha em mente que você não deve usar robots.txt para bloquear páginas de ferramentas de busca. Isso está proibido.)
Um dos melhores usos de arquivo robots.txt é a maximização do limite de rastreamento de ferramentas de busca, ao avisá-las para ignorar partes do seu site que não são vistas pelo público.
Por exemplo, se você visitar o arquivo robots.txt para este site (neilpatel.com), vai ver que a página de login não está ao alcance (wp-admin).
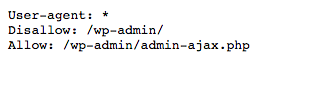
Já que essa página é usada apenas para entrar no site, os robôs não precisam perder tempo com ela.
(Caso você tenha WordPress, pode usar essa mesma linha para desabilitar.)
Você pode usar um diretório (ou comando) parecido para impedir robôs de rastrear páginas específicas. Depois de “disallow”, digite a parte da URL que vem depois de .com. Coloque-a entre duas barras.
Caso não queira que um robô rastreie a página https://seusite.com/page/, é só digitar isto:
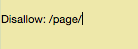
Está em dúvida sobre quais tipos de páginas excluir da indexação? Observe estes exemplos comuns:
Conteúdo duplicado necessário. Conteúdo duplicado não ajuda, mas existem alguns casos em que é necessário e aceitável.
Por exemplo, se você tem uma versão para impressão de uma página, tecnicamente, você tem conteúdo duplicado. Nesse caso, é só avisar aos robôs para não rastrear uma dessas versões (geralmente, a que está pronta para impressão).
Isso também vale para páginas de teste que possuem o mesmo conteúdo, mas designs diferentes.
Páginas de agradecimento. Páginas de agradecimento são algumas das favoritas dos profissionais de marketing porque apontam para um novo contato.
…Certo?
Na verdade, algumas páginas de agradecimento são acessíveis pelo Google. Com isso, as pessoas podem acessar essas páginas sem passar pelo processo de captura de contatos, o que é uma má notícia.
Ao bloquear as suas páginas de agradecimento, você garante que apenas contatos qualificados estejam vendo as páginas.
Digamos que a sua página de agradecimento esteja no link https://seusite.com/thank-you/. Em seu arquivo robots.txt, o bloqueio dessa página fica assim:
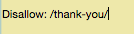
Já que não existem regras universais para quais páginas desabilitar, o seu arquivo robots.txt será único em seu site. Use o seu melhor julgamento aqui.
É bom conhecer também esses outros dois diretivos: noindex e nofollow.
Sabe esse diretivo disallow que estamos usando? Não impede a página de ser indexada.
Na teoria, você pode desabilitar uma página, mas ela ainda pode ser indexada.
De maneira geral, é melhor evitar.
Por isso que você precisa do diretivo noindex. Trabalha com o diretivo disallow para garantir que robôs não visitem ou indexem certas páginas.
Caso não queira indexar certas páginas (como as preciosas páginas de agradecimento), você pode usar os diretivos disallow e noindex:
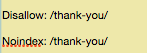
Agora, essa página não vai aparecer nas SERPs.
Por último, o diretivo nofollow. É o mesmo que um link nofollow. Resumindo, avisa aos robôs para não rastrear os links de uma página..
Mas o diretivo nofollow tem que ser implementado de outro jeito, porque não faz parte do arquivo robots.txt.
Entretanto, o diretivo nofollow ainda instrui robôs da internet, então parte do mesmo conceito. A única diferença é onde está localizado.
Encontre o código-fonte da página a ser modificada e certifique-se de estar entre as tags <head>.
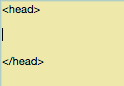
Depois, copie a linha:
<meta name=”robots” content=”nofollow”>
Vai ficar assim:
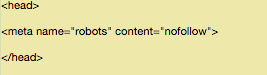
Certifique-se de não estar colocando essa linha entre outras tags além das tags <head>.
Essa é outra boa opção para páginas de agradecimento, já que robôs da internet não irão rastrear links para páginas que chamam novos contatos ou outros conteúdos exclusivos.
Caso queira adicionar os diretivos noindex e nofollow, use esta linha de código:
<meta name=”robots” content=”noindex,nofollow”>
Os robôs da internet verão os dois diretivos ao mesmo tempo.
Testando tudo
Por último, teste o arquivo robots.txt para checar se tudo está funcionando da maneira correta.
O Google tem uma ferramenta de teste gratuita como parte das ferramentas de Webmaster.
Primeiro, entre em sua conta Webmasters clicando em “Entrar” no canto superior direito.
Selecione a sua propriedade (o seu site) e clique em “Rastrear” na barra esquerda.
Você vai ver o “robots.txt Tester”. Clique em cima.
Caso tenha algum código na caixa, delete e coloque o seu novo arquivo robots.txt.
Clique “Teste” na parte inferior direita da tela.
Se o texto “Teste” mudar para “Permitido”, o seu robots.txt é válido.
Aqui estão mais alguma informações sobre a ferramenta, caso queira aprender sobre em mais detalhes.
Por último, faça um upload de seus robots.txt em seu diretório central (ou salve lá caso já tenha um). Agora, você está armado com um arquivo poderoso, logo mais verá um aumento na visibilidade de busca.
Conclusão
Gosto de compartilhar “atalhos” SEO não muito conhecidos que podem trazer algumas vantagens para você.
Ao configurar o seu arquivo robots.txt da maneira correta, você não está só melhorando o seu SEO. Também está ajudando seus visitantes.
Se robôs de ferramentas de busca gastaram o limite de rastreamento de maneira correta, eles vão organizar e expor o seu conteúdo nas SERPs da melhor maneira possível, o que significa que você irá ficar mais visível.
Também não é preciso muito esforço para configurar seu arquivo robots.txt. Geralmente, é apenas uma configuração, e você pode fazer as outras pequenas mudanças quando necessário.
Se está começando o seu primeiro ou quinto site, o uso de robots.txt faz uma grande diferença. Recomendo experimentar caso ainda não tenha feito isso antes.
Qual a sua experiência com a criação de arquivos robots.txt?









