



Wir alle lieben “Tricks”.
Ich bin da keine Ausnahme – Ich finde gern neue Möglichkeiten, um das Leben besser und einfacher zu gestalten.
Darum gehört die Technik, die ich Dir heute vorstellen werde, auch zu meinen absoluten Lieblingstricks. Es ist ein legitimer SEO-Hack, den Du sofort nutzen kannst.
Du kannst Dein SEO verbessern, indem Du einen Teil der Webseite, über den nur sehr selten gesprochen wird, ausnutzt. Die Technik ist auch nicht schwer umzusetzen.
Es handelt sich um die Robots.txt Datei (auch Robots-Exclusion-Standard-Protokoll genannt).
Jede Webseite im Internet hat diese winzig kleine Textdatei, die meisten Leute kennen sie aber nicht einmal.
Die wurde für die Suchmaschinen entwickelt, verfügt aber überraschenderweise über SEO-Juice, der nur darauf wartet, freigeschaltet zu werden.
Ich habe einen Kunden nach dem anderen dabei beobachtet, wie sie sich ein Bein ausreißen, um ihr SEO zu verbessern. Wenn ich ihnen dann sage, dass sie nur eine kleine Textdatei bearbeiten müssen, glauben sie mir fast nicht.
Es gibt viele unkomplizierte und zeitsparende Methoden, mit denen man sein SEO verbessern kann, und diese ist definitiv eine von ihnen.
Du musst keine technischen Vorkenntnisse haben, um die Vorteile der Robots.txt Datei nutzen zu können. Wenn Du den Quelltext Deine Seite finden kannst, kannst Du sie Dir schon zu Nutze machen.
Wenn Du bereit bist, können wir schon loslegen. Ich zeige Dir jetzt, wie Du Deine Robots.txt Datei ändern kannst, damit sie von den Suchmaschinen geliebt wird.
Erfahre hier, wie ich die Kraft des SEO genutzt habe, um 195.013 zusätzliche Besucher pro Monat zu gewinnen.
Warum die Robots.txt Datei so wichtig ist
Zunächst wollen wir uns ansehen, warum die Robots.txt Datei überhaupt so wichtig ist.
Die Robots.txt Datei, Auch bekannt als Robots-Exclusion-Standard-Protokoll, ist eine Textdatei, die den Web-Robotern (meistens Suchmaschinen) sagt, welche Seiten Deiner Webseite durchsucht werden sollen.
Es sagt ihnen auch, welche Seiten nicht durchsucht werden sollen.
Die Suchmaschine will also Deine Seite besuchen. Bevor sie die Zielseite besucht, zieht es die Robots.txt Datei zu Rate.
Es gibt verschiedene Arten von Robots.txt Dateien, darum wollen wir uns jetzt unterschiedliche Beispiele ansehen.
Nehmen wir mal an, die Suchmaschine findet diese Robots.txt Datei:

Das ist das Grundgerüst einer Robots.txt Datei.
Das Sternchen hinter “user-agent” bedeutet, dass die Robots.txt Datei für alle Web- Roboter, die die Seite besuchen, gilt.
Der Schrägstrich hinter “Disallow” sagt dem Roboter, dass er gar keine Seite auf der Webseite besuchen soll.
Du fragst Dich jetzt bestimmt, warum man die Roboter vom Besuchen einer Seite abhalten wollen würde.
Eins der Hauptziele des SEO ist es schließlich, die Suchmaschinen dazu zu bekommen, Deine Seiten leichter zu durchsuchen, damit sie Dein Ranking verbessern können.
Und genau hier kommt dieser SEO-Trick ins Spiel.
Wahrscheinlich hast Du ne Menge Seiten, stimmt’s? Sogar wenn Du nicht der Meinung bist, schau doch mal nach. Du wirst vielleicht überrascht sein.
Wenn eine Suchmaschine Deine Webseite durchsucht, dann wird sie jede einzelne Seite durchsuchen.
Und wenn Du viele Seiten hast, dann braucht der Roboter eine ganze Weile dafür. Das kann Deine Platzierungen negativ beeinflussen.
Das liegt daran, dass dem Google-Bot (der Such-Roboter von Google) nur ein begrenztes “Crawl Budget” zur Verfügung steht.
Dieses “Crawl Budget” besteht aus zwei Teilen. Der erste ist das „Crawl Rate Limit“. Und so beschreibt Google dieses Limit:

Der zweite Teil ist das „Crawl Demand“:

Das Crawl Budget ist also “die Anzahl der URLs, die der Google-Bot durchsuchen kann.”
Du musst dem Google-Bot also dabei helfen, die Zeit auf Deiner Seite sinnvoll einzusetzen. Er sollte nur Deine wichtigsten Seiten durchsuchen.
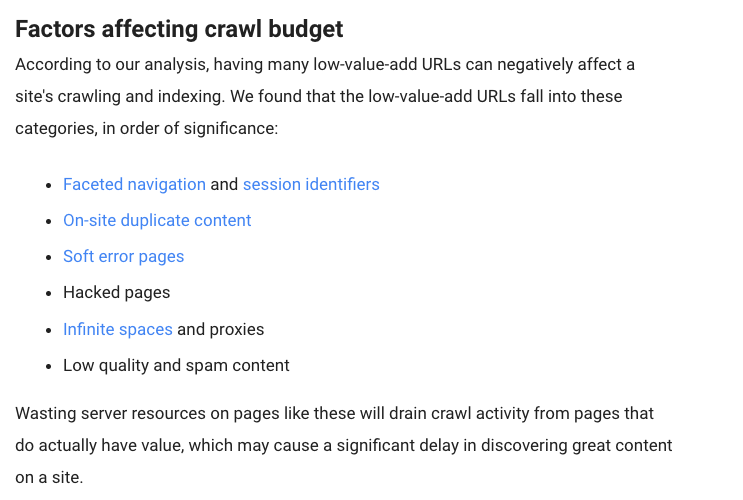
Es gibt aber einige Faktoren, die “das Durchsuchen und Indexieren Deiner Seite negativ beeinflussen”, sagt Google.
Hier sind diese Faktoren:
Kommen wir aber noch mal auf die Robots.txt Datei zurück.
Wenn Du die richtige Robots.txt Seite baust, kannst Du den Such-Bots (besonders dem Google-Bot) sagen, dass sie bestimmte Seiten vermeiden sollen.
Denk mal an die Auswirkungen. Wenn Du den Bots sagst, dass sie nur die wichtigsten Inhalte durchsuchen sollen, werden sie auch nur diese Inhalte für die Indexierung Deiner Webseite nutzen.
“Du solltest Deinen Server nicht mit dem Google-Crawler überlasten oder Dein Crawl Budget für unwichtige Seiten verschwenden.”
Wenn Du die Robots.txt Datei richtig nutzt, kannst Du den Such-Bots dabei helfen, ihr Crawl Budget sinnvoll zu nutzen. Darum ist die Robots.txt Datei so wichtig fürs SEO.
Bist Du jetzt fasziniert von der Wirksamkeit der Robots.txt Datei? Das solltest Du auch! Jetzt zeige ich Dir, wie Du sie finden und nutzen kannst.
Wie Du eine Robots.txt Datei findest
Wenn Du nur mal einen kurzen Blick auf Deine Robots.txt Datei werfen willst, ist das ganz einfach.
Diese Methode funktioniert für jede Seite. Du kannst also auch einen Blick auf andere Webseiten werfen, um zu sehen, was die so machen.
Du musst nur die URL in die Suchleiste Deines Browsers eingeben (z.B. neilpatel.com, quicksprout.com, etc.) und am Ende dann /robots.txt hinzufügen.
Dann passiert eins der folgenden drei Dinge:
1) Du findest eine Robots.txt Datei.
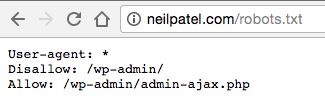
2) Du findest eine leere Datei.
Disney scheint keine Robots.txt Datei zu haben:
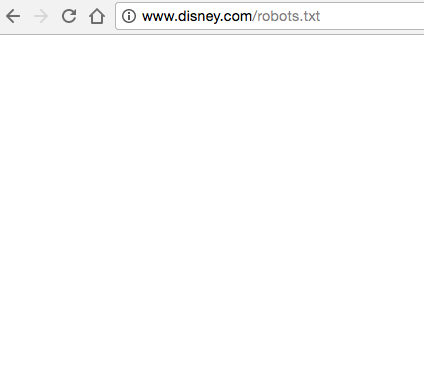
3) Du bekommst einen 404-Fehler.
Method löst einen 404-Fehler aus:
Schau Dir die Robots.txt Datei Deiner Seite an.
Wenn Du eine leere Datei oder einen 404-Fehler findest, solltest Du das reparieren.
Wenn Du eine funktionierende Datei findest, dann hat sie wahrscheinlich die Grundeinstellungen.
Ich benutze diese Methode sehr gern, um mir die Robots.txt Dateien anderer Seiten anzusehen. Wenn Du Dich mit Robots.txt Dateien vertraut machen willst, ist das eine gute Übung.
Jetzt wollen wir uns aber ansehen, wie Du Veränderungen an Deiner Robots.txt Datei vornehmen kannst.
Wie Du Deine Robots.txt Datei findest
Der nächste Schritt ist ganz davon abhängig, ob Du eine Robots.txt Datei hast, oder nicht. (Du kannst das mit der oben besprochenen Methode überprüfen.)
Wenn Du keine Robots.txt Datei hast, musst Du eine erstellen. Öffne ein Programm zur Textbearbeitung (Plaintext-Editor), z.B. Notepad (Windows) oder TextEdit (Mac).
Du darfst nur einen Plaintext-Editor benutzen. Wenn Du ein Programm wie Microsoft Word benutzt, könnte es Deinem Text einen zusätzlichen Code hinzufügen.
Editpad.org ist eine tolle kostenlose Option, darum benutze ich es für diesen Artikel.
Zurück zur Robots.txt Datei. Wenn Du eine Robots.txt Datei hast, musst Du sie im Stammverzeichnis Deiner Seite ausfindig machen.
Wenn Du Dich nicht mit Quelltext auskennst, kann es durchaus schwierig sein, die editierbare Version Deiner Robots.txt Datei zu finden.
Normalerweise findest Du Dein Stammverzeichnis bei Deinem Internetanbieter. Melde Dich in Deinem Konto an und geh zum Verwaltungs- oder FTP-Bereich Deiner Webseite.
Du solltest dann so etwas sehen:
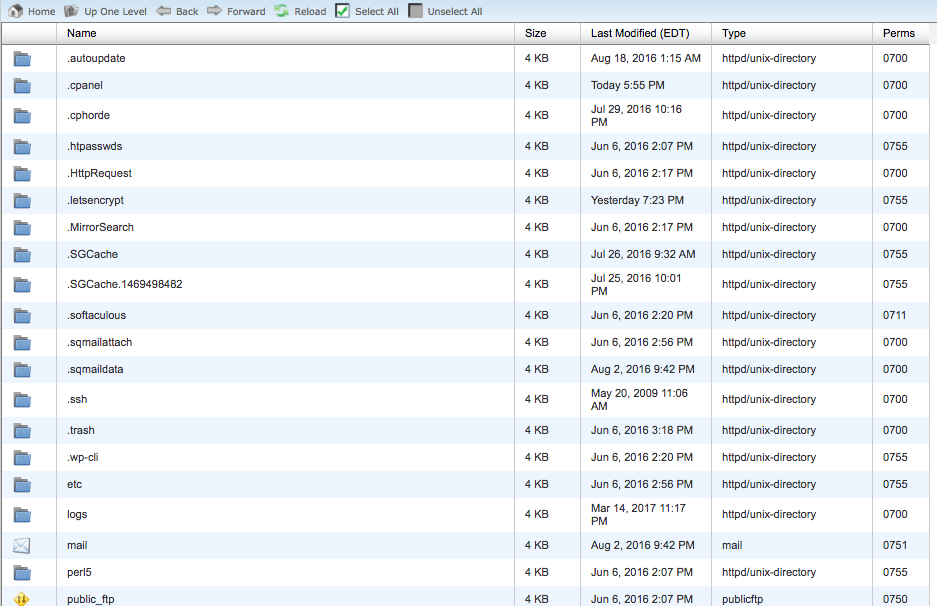
Finde Deine Robots.txt Datei und öffne sie, um sie zu bearbeiten. Lösche den Text, behalte aber die Datei.
Anmerkung: Wenn Du WordPress benutzt, kannst Du Deine Robots.txt Datei zwar sehen, wenn Du deineseite.com/robots.txt eingibst, aber eventuell kannst Du die Datei nicht finden.
Das liegt daran, dass WordPress eine virtuelle Robots.txt Datei erstellt, wenn das Stammverzeichnis keine enthält.
Wenn das bei Dir der Fall ist, musst Du eine neue Robots.txt Datei erstellen.
Die Erstellung Deiner Robots.txt Datei
Du kannst eine neue Robots.txt Datei erstellen, indem Du ein Textbearbeitungsprogramm benutzt. (Denk aber daran, dass Du einen Plaintext-Editor benutzen musst.)
Wenn Du schon eine Robots.txt Datei hast, musst Du den darin vorhandenen Text löschen (nicht aber die Datei selbst).
Du solltest Dich erst mit dem Aufbau einer Robots.txt Datei vertraut machen.
Google stellt eine tolle Erklärung, mit den wichtigsten Robots.txt Begriffen, zur Verfügung:
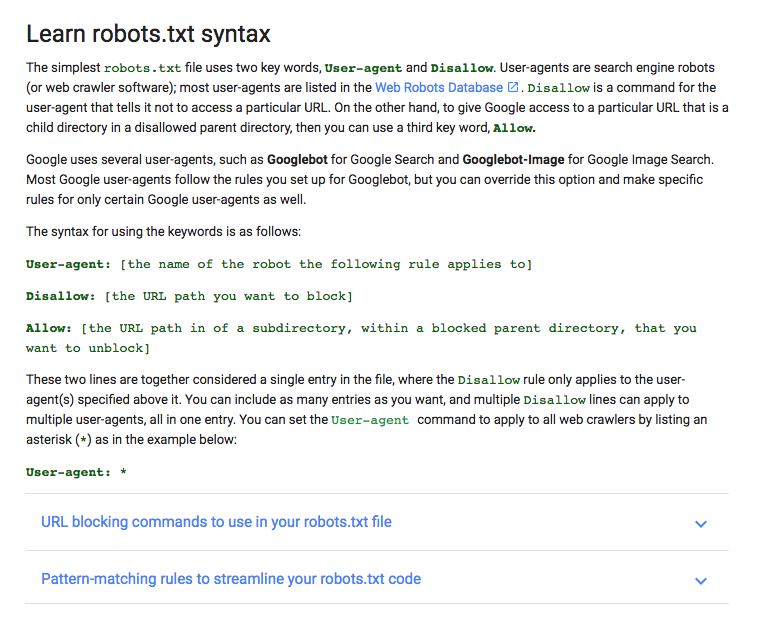
Ich zeige Dir jetzt, wie Du eine Robot.txt Datei anlegen kannst. Dann werde ich Dir erklären, wie Du diese Datei auf Dein SEO zuschneiden kannst.
Zunächst legen wir den User-Agent fest. Wir wollen ihn so anlegen, dass er auf alle Suchmaschinen zutrifft.
Um das zu tun, musst Du das Sternchen hinter dem User-Agent angeben:

Schreib dann “Disallow:”, aber nichts dahinter.

Da nichts hinter „Disallow“steht, werden die Such-Roboter Deine komplette Seite durchsuchen.
Bis jetzt sieht Deine Robots.txt Datei also so aus:

Ich weiß, das sieht super schlicht aus. Diese zwei Zeilen leisten aber schon eine ganze Menge.
Du kannst auch auf Deine XML Sitemap verweisen, musst Du aber nicht. Wenn Du es aber machen willst, gibst Du Folgendes ein:
Und so sieht eine Robots.txt Datei aus.
Jetzt wollen wir aber noch einen Schritt weitergehen und Deine Seite in einen SEO-Booster verwandeln.
Deine Robots.txt Datei fürs SEO optimieren
Wie Du Deine Robots.txt Datei optimierst, hängt ganz vom Inhalt Deiner Webseite ab. Du kannst Deine Robots.txt Datei auf vielerlei Weise zu Deinem Vorteil nutzen.
Ich gehe jetzt ein paar der häufigsten Anwendungen mit Dir durch.
(Denk aber daran, dass Du die Robots.txt Datei nicht nutzen solltest, um Seiten vor den Suchmaschinen zu verstecken. Das wird nicht gern gesehen.)
Du nutzt die Robots.txt Datei am besten, indem Du das Crawl Budget der Suchmaschinen maximierst. Du sagst den Suchmaschinen, dass sie die Seiten, die von Deinen Besuchern nicht gesehen werden, nicht durchsuchen sollen.
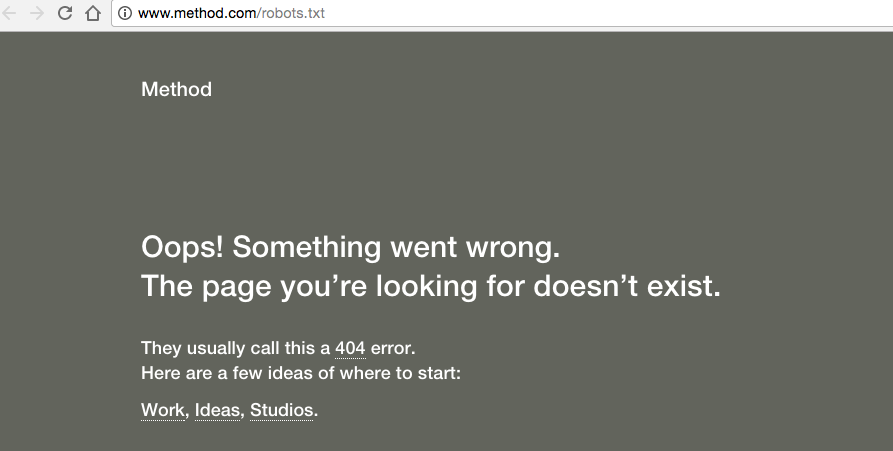
Wenn Du Dir die Robots.txt Datei dieser Seite (neilpatel.com) ansiehst, wirst Du feststellen, dass sie die Login-Seite (wp-admin) ausschließt.
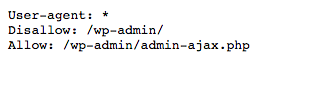
Da diese Seite nur genutzt wird, um sich im Backend der Webseite einzuloggen, macht es keinen Sinn für die Suchmaschinen, ihre Zeit mit dem Durchsuchen dieser Seite zu verschwenden.
(Wenn Du WordPress hast, kannst Du genau den gleichen Disallow-Befehl benutzen.)
Du kannst einen ähnlichen Befehl benutzen, um die Bots vom Durchsuchen bestimmter Seiten abzuhalten. Gib nach dem Disallow einfach den Teil der URL, der nach dem „.com“ kommt, ein. Setzt das Ganze zwischen zwei Schrägstriche.
Wenn Du dem Bot sagst, dass er die Seite https://deineseite.com/seite/ nicht durchsuchen soll, gibst Du das hier ein:
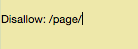
Du fragst Dich jetzt sicher, welche Seiten man ausschließen sollte. Hier sind ein paar der häufigsten Szenarien:
Doppelte Inhalte (Duplicate Content), die absichtlich erstellt wurden. Obwohl doppelte Inhalte meistens etwas Schlechtes sind, sind sie in manchen Fällen notwendig und zulässig.
Wenn Du beispielsweise eine druckfreundliche Version Deiner Seite anbietest, ist das ein duplizierter Inhalt. In diesem Fall kannst Du den Bots sagen, dass sie nur eine Version (normalerweise die druckfreundliche Version) durchsuchen sollen.
Diese Methode ist auch ganz hilfreich, wenn Du einen Split-Test durchführst, um unterschiedliche Designs zu testen.
Vielen-Dank-Seiten. Die Vielen-Dank-Seite zählt zu den Lieblingsseiten eines jeden Vermarkters, weil sie einen neuen Lead bedeutet.
…Richtig?
Wie sich herausstellt, sind einige dieser Seiten mit Google zugänglich. Das heißt, dass Leute auf diese Seite zugreifen können, ohne dem Lead-Gewinnungs-Prozess gefolgt zu sein.Das ist schlecht.
Wenn Du diese Vielen-Dank-Seiten ausschließt, kannst Du dafür sorgen, dass sie nur qualifizierten Leads zugänglich sind.
Wir nehmen jetzt einfach mal an, dass Deine Seite unter https://deineseite.com/thank-you/ zu finden ist. Wenn Du diese Seite mit der Robots.txt Datei ausschließen willst, sieht das so aus:
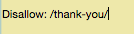
Das es keine universellen Richtlinien gibt, welche Seiten ausgeschlossen werden sollten, und welche nicht, wird die Robots.txt Datei Deiner Seite einzigartig sein. Du musst Deinen gesunden Menschenverstand benutzen.
Es gibt noch zwei weitere Elemente, die Du kennen solltest: Noindex und Nofollow.
Der Disallow-Befehl, den wir benutzt haben, hält die Suchmaschinen nicht unbedingt davon ab, Deine Seite zu indexieren.
Theoretisch könntest Du eine Seite also ausschließen, sie könnte aber dennoch indexierst werden.
Das wollen wir aber nicht.
Darum brauchst Du den Noindex-Befehl. Der funktioniert wie der Disallow-Befehl, sorgt aber dafür, dass die Bots Deine Seiten weder besuchen noch indexieren.
Wenn Du eine Seite hast, die nicht indexiert werden soll (z.B. eine Vielen-Dank-Seite), kannst Du beide, den Disallow- und den Noindex-Befehl, benutzen:
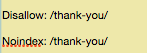
Jetzt taucht diese Seite nicht in den SERPs auf.
Und dann gibt es da noch den Nofollow-Befehl. Das ist das gleiche wie der Nofollow-Link. Dieser Befehl sagt den Web-Bots, dass sie die Links einer Seite nicht durchsuchen sollen.
Der Nofollow-Befehl wird aber anders eingerichtet, weil er nicht zur Robots.txt Datei gehört.
Dennoch gibt der Nofollow-Befehl den Web-Robotern Anweisungen, folgt also demselben Konzept. Die Einstellungen werden nur an einem anderen Ort vorgenommen.
Finde den Quelltext der Seite, die Du ändern willst, und setzt den Cursor zwischen die beiden <head> Tags.
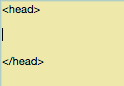
Füge diese Zeile ein:
<meta name=“robots“ content=“nofollow“>
Das sollte dann so aussehen:
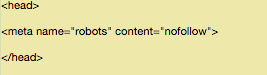
Füge die Zeile auf keinen Fall zwischen zwei anderen Tags ein – nur zwischen den <head> Tags.
Auch das ist eine gute Möglichkeit für Deine Vielen-Dank-Seite, weil die Web-Roboter kann keine Lead-Magneten oder exklusiven Inhalte durchsuchen.
Wenn Du beides, Noindex- und Nofollow-Befehl, hinzufügen willst, benutze diesen Code:
<meta name=“robots“ content=“noindex,nofollow“>
Dann erhalten die Web-Bots beide Befehle auf einmal.
Teste alles
Jetzt musst Du Deine Robots.txt Datei noch testen, um sicherzugehen, dass alles richtig eingestellt ist und läuft.
Google stellt einen kostenlosen Robots.txt Tester in den Webmaster Tools zur Verfügung.
Melde Dich in Deinem Webmasters Konto an, indem Du in der oberen rechten Ecke auf “Anmelden” klickst.
Wähle Deine Property (z.B. Website) aus und klick auf “Crawling” in der rechten Seitenleiste.
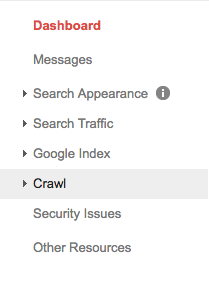
Hier findest Du den “robots.txt-Tester.” Klick da drauf.
Wenn die Box schon einen Code enthält, kannst Du ihn löschen und Deine neue Robots.txt Datei einfügen.
Klick auf “Testen” in der unteren rechten Ecke.
Wenn “Testen” dann zu “Zugelassen” wird, ist Deine Robots.txt Datei gültig.
Hier sind noch mehr Informationen über das Tool, wenn Du mehr ins Detail gehen möchtest.
Lade Deine Robots.txt Datei dann im Stammverzeichnis hoch (oder speichere sie dort, wenn Du schon eine hattest). Jetzt hast Du eine wirksame Datei, die Deine Sichtbarkeit in der Suche deutlich verbessern sollte.
Fazit
Ich liebe es, solch eher unbekannte SEO-“Tricks”, die Dir ein paar echte Vorteile verschaffen können, zu teilen.
Wenn Du Deine Robots.txt Datei richtig einrichtest, verbesserst Du nicht nur Dein SEO. Du hilfst auch Deinen Besuchern.
Wenn die Suchmaschinen ihr Crawl Budget weise nutzen können, dann organisieren und zeigen sie Deine Inhalte auch besser in den SERPs, wodurch Du mehr Sichtbarkeit erlangst.
Es ist auch nicht viel Arbeit so eine Robots.txt Datei zu erstellen. Es ist eine einmalige Einstellung, die Du entsprechend Deiner Bedürfnisse anpassen kannst.
Ganz egal, ob Du Deine erste oder fünfzigste Webseite baust, die Robots.txt Datei kann einen entscheidenden Unterschied machen. Ich kann es Dir nur empfehlen, wenn Du es nicht schon längst gemacht hast.
Hast Du schon Erfahrungen mit Robots.txt Dateien gesammelt?

See How My Agency Can Drive More Traffic to Your Website
- SEO – unlock more SEO traffic. See real results.
- Content Marketing – our team creates epic content that will get shared, get links, and attract traffic.
- Paid Media – effective paid strategies with clear ROI.
Schalte mit Ubersuggest Tausende von Keywords frei
Bist Du bereit, Deine Konkurrenten zu überholen?
- Finde Long-Tail-Keywords mit hohem ROI
- Entdecke sofort Tausende von Keywords
- Verwandele Suchanfragen in Besucher und Conversions
Kostenloses Keyword-Tool







