

Todos aman los «hacks».
No soy la excepción––Me encanta encontrar maneras de hacer mi vida mejor y más fácil.
Es por esto que la técnica que te voy a contar hoy es una de mis favoritas. Es un hack de SEO que puedes comenzar a usar inmediatamente.
Es una manera de incrementar tu SEO al aprovechar una parte natural de cada sitio web que muy raramente se menciona. Tampoco es difícil implementarla.
Es el archivo robots.txt (también llamado protocolo o estándar para la exclusión de los robots).
Este pequeño archivo de texto es parte de cada sitio web en internet, pero la mayoría de las personas no lo conocen.
Está diseñado para funcionar con los motores de búsqueda, pero sorprendentemente, es una fuente poder SEO que está esperando a ser descubierta.
He visto a muchos clientes hacer de todo para mejorar el SEO de su sitio web. Cuando les digo que pueden editar un pequeño archivo de texto, casi no me creen.
Sin embargo, existen muchos métodos para mejorar tu SEO que no son difíciles ni te quitan mucho tiempo, y éste es uno de ellos.
No necesitas tener ninguna experiencia técnica para aprovechar el poder de los robots.txt. Si puedes encontrar el código fuente para tu sitio web, puedes utilizar esto.
Cuando estés listo, sígueme y te explicaré la manera en la que puedes cambiar tu archivo de robots.txt para que a los motores de búsqueda les guste.
Descubre cómo aproveché el SEO para generar 195,013 visitantes adicionales al mes.
Por qué el archivo robots.txt es importante
Primero, echemos un vistazo al porqué es importante el archivo robots.txt.
El archivo robots.txt, también conocido como el protocolo o estándar de exclusión de robots, es un archivo de texto que les dice a los robots web (motores de búsqueda) qué páginas de tu sitio deben rastrear.
También les dice a los robots web qué páginas no deben rastrear.
Supongamos que un motor de búsqueda está a punto de visitar un sitio web. Antes de que visite la página objetivo, comprobará el archivo de robots.txt para recibir instrucciones.
Existen distintos tipos de archivos robots.txt, así que echemos un vistazo a los diferentes tipos de apariencia que tienen.
Digamos que el motor de búsqueda encuentra este ejemplo de archivo robots.txt:

Esta es la columna vertebral del archivo robots.txt.
El asterisco después de «user-agent» significa que el archivo robots.txt está abierto a todos los robots que visiten el sitio web.
La diagonal después de «Disallow» le dice al robot que no visite ninguna página en el sitio web.
Quizá te estés preguntando por qué alguien querría evitar que los robots web visitaran su sitio web.
Después de todo, uno de los principales objetivos del SEO es lograr que los motores de búsqueda rastreen tu sitio web de una manera más sencilla para incrementar tus rankings.
Aquí es donde se encuentra el secreto de este hack de SEO.
Probablemente tengas muchas páginas en tu sitio web, ¿verdad? Incluso si consideras que no es así, revísalo. Quizá te sorprendas.
Si un motor de búsqueda rastrea tu sitio web, éste rastreará cada una de tus páginas.
Y si tienes muchas páginas, le llevará mas tiempo rastrearlas al bot del motor de búsquedas, lo que tendrá efectos negativos en tu ranking.
Esto es debido a que el Googlebot (el bot del motor de búsqueda de Google) tiene un «presupuesto de rastreo.»
Esto se divide en dos partes. El primero es una tasa límite de rastreo. Así es como lo explica Google:

La segunda parte es una demanda de rastreo:

Básicamente, el presupuesto de rastreo es «el número de URLs que el Googlebot puede y quiere rastrear».
Necesitas ayudar al Googlebot a invertir su presupuesto de rastreo para tu sitio web de la mejor manera posible. En otras palabras, debería emplear el tiempo en rastrear tus páginas más valiosas.
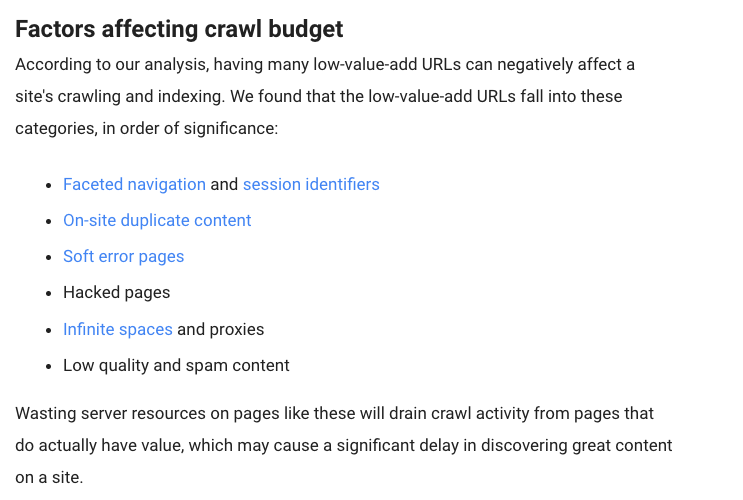
Existen ciertos factores que, de acuerdo con Google, «afectarán negativamente el rastreo y la indexación de un sitio web.»
Estos son esos factores:
Volvamos al archivo robots.txt.
Si creas la página correcta de robots.txt, puedes decirle a los bots de los motores de búsqueda (y especialmente al Googlebot) que eviten ciertas páginas.
Piensa en lo que esto implica. Si le dices a los bots de los motores de búsqueda que solamente rastreen tu contenido más útil, los bots rastrearán e indexarán tu sitio con el foco en ese contenido solamente.
«No quieres que tu servidor se sienta abrumado por el rastreador de Google o desperdiciar presupuesto de rastreo al rastrear páginas no importantes en tu sitio web.»
Al usar tu robots.txt de la manera correcta, puedes decirle a los bots de los motores de búsqueda que inviertan su presupuesto de rastreo inteligentemente. Y eso es lo que hace que el archivo robots.txt sea tan útil en un contexto de SEO.
¿Te sientes intrigado por el poder de los robots.txt?
¡Pues deberías! Hablemos sobre cómo encontrarlo y usarlo.
Encuentra tu archivo robots.txt
Si sólo quieres echar un rápido vistazo a tu archivo robots.txt, existe una manera súper fácil.
De hecho, este método funcionará con cualquier sitio web. Por lo que puedes echar un vistazo a los archivos de otros sitios web y ver lo que están haciendo.
Lo único que tienes que hacer es teclear la URL básica del sitio web en la barra de búsquedas de tu navegador (ejemplo: neilpatel.com, quicksprout.com, etc). Y después agregar /robots.txt al final.
Te encontrarás con una de estas tres situaciones:
1) Encontrarás un archivo robots.txt.
2) Encontrarás un archivo vacío.
Por ejemplo, parece que Disney no tiene un archivo robots.txt:
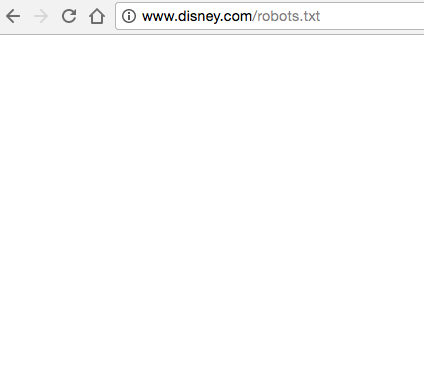
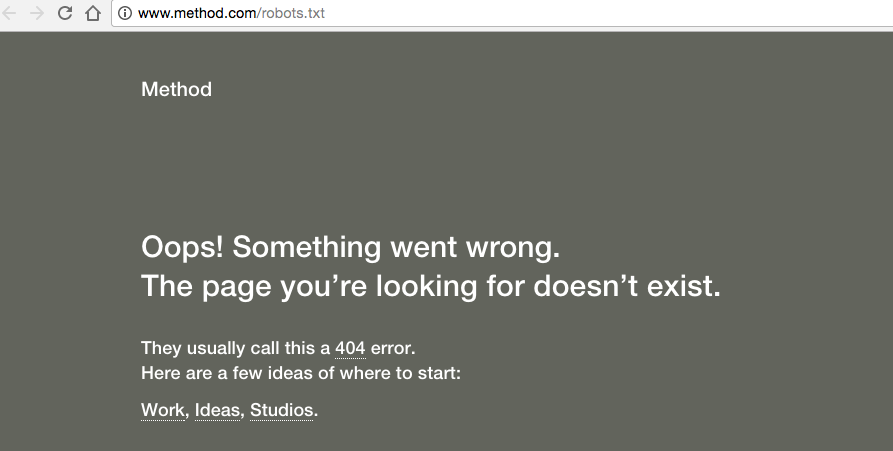
3) Obtendrás un error 404.
Method muestra un error 404 con archivos robots.txt:
Echa un segundo vistazo a tu propio archivo de robots.txt.
Si encuentras un archivo vacío o un error 404, necesitarás solucionarlo.
Si encuentras un archivo válido, probablemente tiene la configuración predeterminada que fue creada cuando hiciste tu sitio web.
Me gusta este método especialmente para ver los archivos robots.txt de otros sitios web. Una vez que aprendas cómo funcionan los archivos robots.txt, este método puede ser un valioso ejercicio.
Ahora veamos cómo cambiar tu archivo robots.txt.
Encuentra tu archivo robots.txt
Tus siguientes pasos van a depender de si tienes un archivo robots.txt. (Revisa si lo tienes al usar el método que describí anteriormente).
Si no tienes un archivo robots.txt, necesitarás crear uno desde cero. Abre un editor de texto como el Bloc de Notas (en Windows) o TextEdit (Mac).
Solamente usa un editor de texto plano para esto. Si usas programas como Microsoft Word, el programa podría insertar código adicional al texto.
Editpad.org es una excelente opción gratuita, y es lo que me verás usando en este artículo.
Volvamos a los robots.txt. Si tienes un archivo robots.txt, necesitarás ubicarlo en el directorio root de tu sitio web.
Si no estás acostumbrado a adentrarte en el código fuente, podría ser un poco difícil ubicar la versión editable de tu archivo robots.txt.
Normalmente, puedes encontrar tu directorio root al ir al sitio web de tu proveedor de hosting, entrar, e ir a la sección de administración de archivos o FTP de tu sitio web.
Deberías ver algo así:
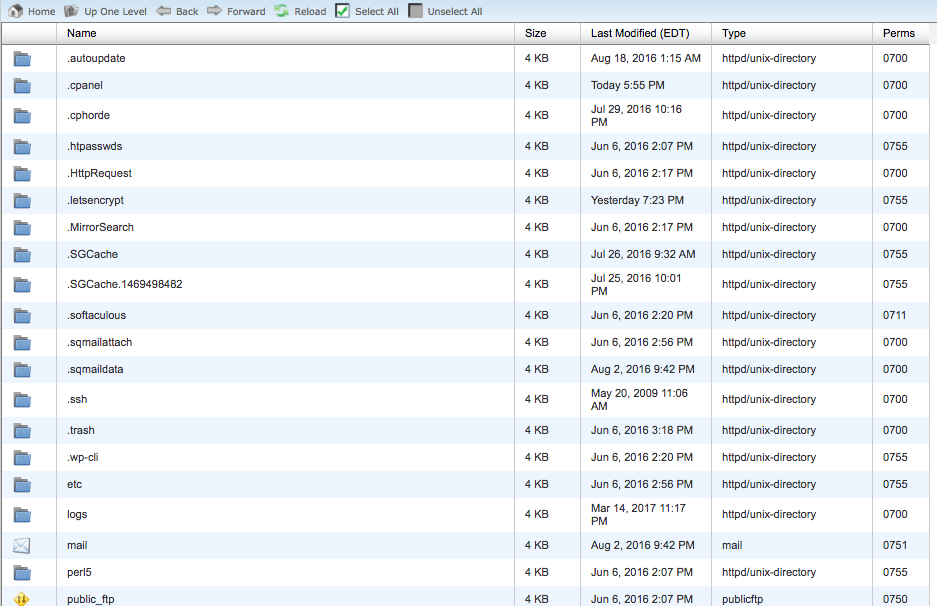
Encuentra tu archivo robots.txt y ábrelo para editarlo. Borra todo el texto, pero mantén el archivo.
Nota: Si estás usando WordPress, quizá veas un archivo robots.txt cuando vayas a tusitio.com/robots.txt, pero no podrás encontrarlo en tus archivos.
Esto es debido a que WordPress crea un archivo robots.txt si no hay robots.txt en el directorio root.
Si esto te sucede, necesitarás crear un nuevo archivo robots.txt.
Crea un archivo robots.txt
Puedes crear un nuevo archivo robots.txt al usar el editor de texto plano que elijas. (Recuerda, usa solamente un editor de texto plano).
Si ya tienes un archivo robots.txt, asegúrate de que has borrado el texto (pero no el archivo).
Primero, necesitarás familiarizarte con algo de la sintaxis usada en un archivo robots.txt.
Google tiene una buena explicación de algunos de los elementos básicos de robots.txt:
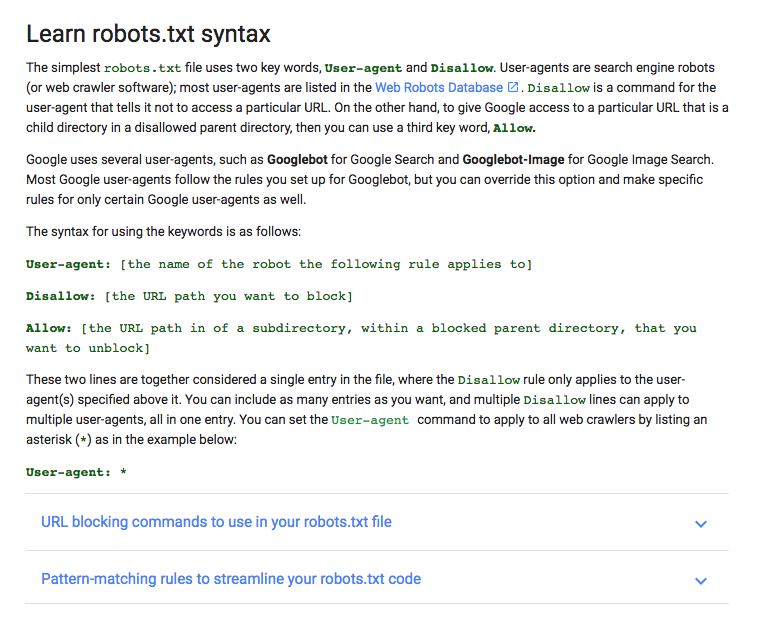
Te voy a mostrar cómo configurar un archivo robots.txt sencillo, y después echaremos un vistazo a cómo personalizarlo para tu SEO.
Comienza fijando el término user-agent. Vamos a configurarlo de manera que esté abierto a todos los robots web.
Puedes lograr esto al usar un asterisco después del término user-agent, así:

Después, teclea «Disallow:» pero no teclees nada después de eso.

Debido a que no hay nada después de disallow, los robots web se dirigirán a rastrear todo tu sitio web. En este momento, todos los elementos de tu sitio web serán vulnerables.
Hasta este momento, tu archivo robots.txt debería verse así:

Sé que se ve súper sencillo, pero estas dos líneas están haciendo mucho por tu sitio web.
También puedes crear un enlace a tu mapa de sitio XML, pero no es necesario. Si quieres, esto es lo que puedes escribir:
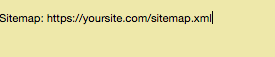
Aunque no lo creas, así debería verse un archivo robots.txt básico.
Ahora llevemos esto al siguiente nivel y convirtamos este pequeño archivo en un potenciador SEO.
Optimiza los robots.txt para SEO
El cómo optimices tus robots.txt depende del contenido que tengas en tu sitio. Existen tres tipos de maneras en las que puedes usar los robots.txt a tu favor.
Voy a ver contigo algunas de las maneras más comunes de usarlo.
(Ten en cuenta que no deberías usar robots.txt para bloquear páginas de los motores de búsqueda. Eso sería un gran no-no).
Uno de los mejores usos del archivo robots.txt es maximizar los presupuestos de rastreo de los motores de búsqueda al decirles que no rastreen las partes de tu sitio web que no se muestran públicamente.
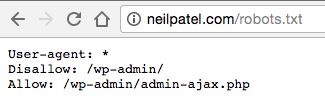
Por ejemplo, si visitas el archivo robots.txt de este sitio (neilpatel.com), verás que tiene bloqueada la página de login (wp-admin).
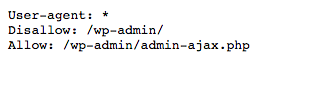
Debido a que esta página se utiliza para entrar a la parte privada del sitio web, no tendría mucho sentido para los bots de los motores de búsqueda desperdiciar su tiempo rastreándola.
(Si tienes WordPress, puedes usar exactamente la misma línea disallow).
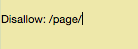
Puedes usar una indicación similar (o comando) para evitar que los bots rastreen páginas específicas. Después del disallow, introduce la parte de la URL que viene después del .com. Coloca eso entre las dos diagonales.
Si quieres decirle a un bot que no rastree tu página https://tusitio.com/página/, puedes teclear esto:
Quizá te estés preguntando qué tipos de páginas deberías excluir de indexación. Aquí hay un par de escenarios comunes en donde esto puede suceder:
Contenido intencionalmente duplicado. Si bien el contenido duplicado es en gran parte algo malo, existen unos cuantos casos en los que es necesario y aceptable.
Por ejemplo, si tienes una versión imprimible de tu página, técnicamente tienes contenido duplicado. En este caso, podrías decirle a los bots que no rastreen una de esas versiones (normalmente, la versión imprimible).
Esto es muy útil si estás haciendo split testing con páginas que tienen el mismo contenido pero diseños distintos.
Páginas de gracias. La página de GRACIAS es una de las páginas favoritas de los marketers porque significa un nuevo lead.
¿Verdad?
Al parecer, algunas páginas de gracias son accesibles a través de Google. Esto significa que la gente puede acceder a estas páginas sin pasar por el proceso de captura de leads, y esto no es bueno.
Al bloquear tus páginas de gracias, puedes asegurarte de que solamente los leads cualificados estén viéndolas.
Pongamos que tu página de gracias se encuentra en https://tusitio.com/gracias. En tu archivo robots.txt, bloquear esa página se vería así:
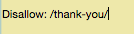
Debido a que no hay reglas universales para saber qué páginas desautorizar, tu archivo robots.txt será único en tu sitio web. Usa tu propio criterio aquí.
Existen otros dos tipos de comandos que deberías conocer: noindex y nofollow.
¿Sabes qué comando disallow hemos estado usando? En realidad no evita que esa página sea indexada.
En teoría, podrías desautorizar una página, pero aun así, podría terminar en el índice.
Generalmente, no te interesa eso.
Es por eso que necesitas el comando noindex, que funciona con el comando disallow para asegurar que no los bots no visiten o indexen ciertas páginas.
Si tienes algunas páginas que no quieres que se indexen (como las páginas de gracias), puedes usar ambos comandos, disallow y noindex:
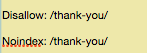
Ahora sí, esa página no se mostrará en las SERPs.
Finalmente, tenemos el comando nofollow. De hecho, es la mismo que el enlace nofollow. En resumen, le dice a los robots web que no rastreen los enlaces en una página.
Pero el comando nofollow vamos a implementarlo de una manera un poco distinta, porque en realidad no forma parte del archivo robots.txt.
Sin embargo, el comando nofollow sigue dando indicaciones a los robots web, por lo que es el mismo concepto. La única diferencia radica en dónde se implementa.
Encuentra el código fuente de la página que quieras cambiar, y asegúrate de que esté entre las etiquetas <head>.
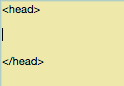
Después, pega esta línea:
<meta name=»robots» content=»nofollow»>
De manera que se vea así:
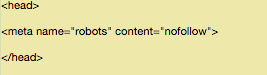
Asegúrate de no estar poniendo esto entre alguna otra etiqueta––sólo las etiquetas <head>.
Esta es otra excelente opción para tus páginas de gracias, debido a que los robots web no rastrearán enlaces a ningún imán de leads u otro contenido exclusivo.
Si quieres agregar ambos comandos: noindex y nofollow, usa esta línea de código:
<meta name=»robots» content=»noindex,nofollow»>
Esto le dará a los robots web ambos comandos al mismo tiempo.
Haz pruebas con todo
Finalmente, haz pruebas con tu archivo robots.txt para estar seguro de que todo es válido y funciona de la manera correcta.
Google pone a tu disposición un ecosistema de pruebas para robots.txt como parte de sus herramientas para Webmasters.
Primero, entra en tu cuenta de Webmasters al hacer clic en «Acceder» en la esquina superior derecha de tu pantalla.
Selecciona tu propiedad (ejemplo: sitio web) y haz clic en «Rastrear» al lado izquierdo de tu pantalla.
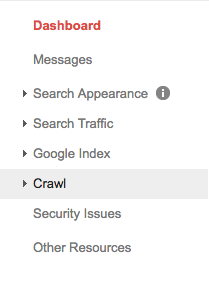
Verás el tester de «robots.txt.» Haz clic ahí.
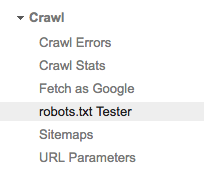
Si ya hay algún código en esa sección, bórralo y reemplázalo con tu nuevo archivo robots.txt.
Haz clic en «Probar» en la esquina inferior derecha de la pantalla.
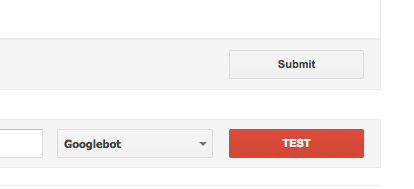
Si el texto de «Probar» cambia a «Permitido,» eso significa que tu archivo robots.txt es válido.
Aquí tienes algo de información sobre la herramienta para que puedas aprender qué significa todo con más detalle.
Finalmente, sube tu archivo robots.txt a tu directorio root (o guárdalo ahí si ya tenías uno). Ahora tendrás como arma un poderoso archivo, y deberías ver un incremento en tu visibilidad de búsqueda.
Conclusión
Siempre me gusta compartir pequeños «hacks» de SEO que te pueden dar una ventaja real de muchas maneras.
Al configurar tu archivo robots.txt correctamente, no sólo estás mejorando tu SEO. También estás ayudando a tus usuarios.
Si los bots de los motores de búsqueda pueden utilizar sus presupuestos de rastreo inteligentemente, organizarán y mostrarán tu contenido en las SERPs de una mejor manera, lo que significa que tendrás mayor visibilidad.
Tampoco lleva mucho esfuerzo para configurar tu archivo robots.txt. Podríamos decir que es una configuración que se hace una sola vez, y puedes hacer tantos pequeños cambios como necesites por el camino.
Ya sea con tu primer sitio web o con el quinto, usar robots.txt puede suponer una diferencia significativa. Te recomiendo darle una vuelta si no lo has hecho antes.
¿Cuál es tu experiencia al crear archivos robots.txt?

See How My Agency Can Drive More Traffic to Your Website
- SEO – unlock more SEO traffic. See real results.
- Content Marketing – our team creates epic content that will get shared, get links, and attract traffic.
- Paid Media – effective paid strategies with clear ROI.
Descubre miles de palabras clave con Ubersuggest
¿Quieres vencer a la competencia?
- Encuentra palabras clave de cola larga con un alto ROI
- Encuentra miles de palabras clave
- Transforma las búsquedas en visitas y ventas
Herramienta gratuita







